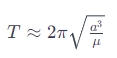时间格式 RFC3339及 ISO8601备注
ISO 8601
包含多种日期和时间的表示格式,其中一些常见的格式包括
- 日期格式:
- 完整日期:
YYYY-MM-DD(例如:2024-01-22)
- 带星期几的日期:
YYYY-Www-D 或 YYYY-Www(例如:2024-W03-5 表示2024年第3周的星期五)
- 年份和季度:
YYYY-Qn(例如:2024-Q1 表示2024年第1季度)
- 时间格式:
- 完整时间:
THH:mm:ss(例如:T11:17:53)
- 时区:
±HH:mm 或 Z(例如:+0800 表示东八区,Z 表示UTC)
- 日期和时间的组合:
- 完整日期和时间:
YYYY-MM-DDTHH:mm:ss(例如:2024-01-22T11:17:53)
- 包含时区的日期和时间:
YYYY-MM-DDTHH:mm:ss±HH:mm 或 YYYY-MM-DDTHH:mm:ssZ
- 时间间隔和持续时间:
- 时间间隔:
PnYnMnDTnHnMnS(例如:P1Y2M3DT4H5M6S 表示1年2个月3天4小时5分钟6秒)
- 持续时间:
PnW(例如:P3W 表示3周)
在 ISO 8601 标准中,时区信息可以使用两种不同的格式表示:一种是带冒号的格式(+08:00),另一种是不带冒号的格式(+0800)。这两种格式都是合法的 ISO 8601 表示。
关于冒号
对于时区信息,ISO 8601 允许使用两种不同的符号分隔小时和分钟部分:
- 带冒号的格式(
+08:00):
+ 表示东时区,- 表示西时区。08 表示小时部分。00 表示分钟部分。
- 不带冒号的格式(
+0800):
+ 表示东时区,- 表示西时区。0800 表示小时和分钟部分。
这两种格式在表示时区时是等效的,可以根据需要选择使用其中之一。在一些系统和应用程序中,会选择使用不带冒号的格式,因为它更简洁。而有些系统和应用程序则更喜欢带冒号的格式,因为它更符合人们的阅读习惯。
rfc3339 ,iso8601 区别
RFC 3339 是 Internet Engineering Task Force(IETF)发布的一份规范,它定义了一种日期和时间的表示格式。这个格式在很大程度上与 ISO 8601 相似,但 RFC 3339 有一些微小的区别和规定,以适应互联网标准的需要。以下是 RFC 3339 与 ISO 8601 的一些主要区别:
- 时区表示方式:
- RFC 3339 要求时区信息使用冒号分隔小时和分钟,即
±HH:MM 的格式。例如,东八区表示为 +08:00。
- ISO 8601 允许时区信息使用带冒号或不带冒号的两种格式,即
±HH:MM 或 ±HHMM。
- 秒的小数部分:
- RFC 3339 要求秒的小数部分只包括 3 位,即毫秒级别的精度。例如,表示毫秒的小数部分为
.123。
- ISO 8601 允许秒的小数部分包括更多的位数,提供更高的精度。
- 日期和时间的分隔符:
- RFC 3339 使用
T 作为日期和时间的分隔符,与 ISO 8601 的标准格式相同。
- ISO 8601 允许使用
T 或空格作为日期和时间的分隔符。
总体而言,RFC 3339 是一种基于 ISO 8601 的日期和时间表示格式,它对互联网应用做出了一些特殊规定以适应网络标准的需要。在实际应用中,RFC 3339 与 ISO 8601 通常可以互换使用,但在特定的上下文中,可能会根据标准的要求选择使用其中一种。
参考:
https://en.wikipedia.org/wiki/ISO_8601
https://www.jianshu.com/p/a14c0858e9c6
https://www.iso.org/iso-8601-date-and-time-format.html
https://web.archive.org/web/20171020084445/https://www.loc.gov/standards/datetime/ISO_DIS%208601-1.pdf
https://web.archive.org/web/20171020084445/https://www.loc.gov/standards/datetime/ISO_DIS%208601-1.pdf