
RPC(Remote Procedure Call,远程过程调用)框架是分布式服务的基石,实现RPC框架需要考虑方方面面。其对业务隐藏了底层通信过程(TCP/UDP、打包/解包、序列化/反序列化),使上层专注于功能实现;框架层面,提供各类可选架构(多进程/多线程/协程);应对设备故障(高负载/死机)、网络故障(拥塞/网络分化),提供相应容灾措施。
RPC节点间为了协同工作、实现信息交换,需要协商一定的规则和约定,例如字节序、压缩或加密算法、各字段类型。通信协议的应用随处可见,例如我们对可选信息或字段经常使用TLV进行编码,HTTP、FTP等协议基于可读文本的 "Field: Value" 格式,各种系统也经常使用json、XML格式完成相互间通信。
不同的通信协议适用于不同的应用场景,比如内部系统的交互我们选择json,一来可读性较好,二来各种语言都提供了解析json的库、方便编码。Google Protocol Buffers是生成环境中常用的通信协议,除了可以设定Client/Server间通信格式,Protocol Buffers还对数据进行压缩,节省传输流量、加快传输速度。下面我们来了解Google Protocol Buffers。
Protocol Buffers
我们看如何使用Protocol Buffers(以下简称PB),首先在.proto文件中定义数据格式,下面以Person.proto为例:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
enum PhoneType {
MOBILE = 0;
HOME = 1;
WORK = 2;
}
message PhoneNumber {
required string number = 1;
optional PhoneType type = 2 [default = HOME];
}
repeated PhoneNumber phone = 4;
}
完成数据定义后,接下来可以使用protoc工具解析Person.proto文件,生成Person类:
protoc --cpp_out=/home/bangerlee/PB ./Person.proto
执行以上命令后,可以看到 /home/bangerlee/PB 目录下生成了两个文件:
person.pb.cc person.pb.h
其中定义了操作(get/set)Person类各个字段的函数。
有了接口,我们就可以在代码中这样使用Person类,写入操作如下:
Person person;
person.set_name("bangerlee");
person.set_id(1234);
person.set_email("bangerlee@gmail.com");
fstream output("myfile", ios::out | ios::binary);
person.SerializeToOstream(&output);
fstream input("myfile", ios::in | ios::binary);
Person person;
person.ParseFromIstream(&input);
cout << "Name: " << person.name() << endl;
cout << "E-mail: " << person.email() << endl;
以上我们初步了解了如何使用PB,PB运用了一些编码规则,使得需要传输的数据(二进制格式)更小,下面我们就来了解PB如何对不同数据类型的编码规则。
编码(Encoding)
对整形int、字符串类型string等,PB有不同的编码方式。对整型int,PB使用了Varints编码方式,Varints编码的优势是使用了更少的bytes来表示很小的int类型值。
Varints编码方式中,每个byte的最高位bit有特殊含义,如果为1,表示后续的byte也是这个数字的一部分;如果为0,则表示结束。剩余的7个bit用于表示数据。数字300用Varints编码方式表示为:
1010 1100 0000 0010
由Varints编码规则,去掉第一个byte的最高位1,去掉第二个byte的最高位0,则有:
1010 1100 0000 0010 → 010 1100 000 0010
Varints字节序使用little-endian,以上数字用big-endian并转换成10进制有:
000 0010 010 1100 → 000 0010 ++ 010 1100 → 100101100 → 256 + 32 + 8 + 4 = 300
以上了解了Varints对int整型的编码方式,我们再来看PB如何编码更多数据类型:
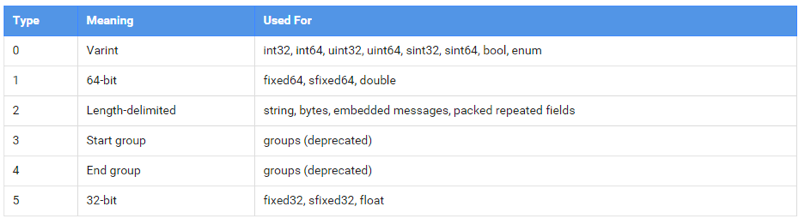
PB编码中,数据以key-value的形式表示,第一个byte即为key。以上表格中不同数据类型对应指定type值,假设message中各字段的数字标识为tag,则key、type和tag有以下对应关系:
key = tag << 3 | type
即key的最后3个bit用于存储type,有了这层关系,我们试着演算PB中对int和string的编码。
假设我们截获到以下PB数据:
08 96 01
这段数据具体表示什么?我们用以上对应关系演算一下,首先该数据key是08,二进制表示即:
0000 1000
最后3个bit表示type,即type为0(Varint格式数据),左移3位得到tag值为1。有了这些信息,我们可以知道这个数据应该是这样定义的:
message Test1 {
xxx int32 a = 1;
}
继续地,我们用Varint格式来解析 96 01,有以下演算过程:
96 01 = 1001 0110 0000 0001
→ 000 0001 ++ 001 0110 (丢弃最高位的bit并转为big-endian)
→ 10010110
→ 2 + 4 + 16 + 128 = 150
因此我们可以知道这段数据表示150这个数。
又假设我们截获到以下一段PB编码:
12 07 74 65 73 74 69 6e 67
同样套用以上关系,key是12,二进制表示即:
0001 0010
最后3个bit表示type,即type为2(Length-delimited),左移3位得到tag值为2。有了这些信息,我们知道这个数据可能是这样定义的:
message Test2 {
xxx string b = 2;
}
数据类型具体是string、bytes或其他,这并不影响我们解析这段数据,对于Length-delimited格式数据,第2个byte表示数据长度(Len),对应以上编码即Len为7,这实质是TLV编码格式。
后续的7个bytes表示有效的传输数据,为UTF-8编码下的"testing"字符串。
小结
以上介绍了通信协议 - Google Protocol Buffers,了解了其基本使用方法和编码方式。PB支持前向兼容,可以在不修改Client/Server程序的情况下修改其中一端的数据格式,在各种RPC框架中经常可以看到它的身影。
Reference: Protocol Buffers Developer Guide