
C# 3.0新语言特性和改进包括:
- 自动属性(Auto-Implemented Properties)
- 隐含类型局部变量(Local Variable Type Inference)
- 匿名类型(Anonymous Types)
- 对象与集合初始化器(Object and Collection Initializers)
- 扩展方法(Extension Methods)
- Lambda表达式和Lambda表达式树 (Lambda Expression and Lambda Expression Trees)
自动属性(Auto-Implemented Properties)
自动属性可以避免原来这样我们手工声明一个私有成员变量以及编写get/set逻辑,在VS2008中可以像下面这样编写一个类,编译器会自动地生成私有变量和默认的get/set 操作。你也可以分别定义get和set的“protected”等访问级别。
在.Net2.0框架下,我们可以这样写一个User类:
public class User{ private int _id; private string _name; private int _age; public int Id { get { return _id; } set { _id = value; } } public string Name { get { return _name; } set { _name = value; } } public int Age { get { return _age; } set { _age = value; } } }
现在,可以这样简化:
public class User{ public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } }
像上面这样的空的get/set属性的话,它会自动为你在类中生成一个私有成员变量,对这个变量实现一个公开的getter 和setter。我们可以使用.NET开发环境所提供的ildasm.exe(IL代码反汇编器)工具来分析程序集或者模块的内容。我就不贴图了。
隐含类型局部变量(Local Variable Type Inference)
C#3.0引进了var这个新关键字,在声明局部变量时可用于替代原先的类型名,即当一个变量声明标识为var类型并且该范围域中没有var名称类型存在,那么这个声明就称为隐含类型局部变量。如下(等同于//后面的显式声明):
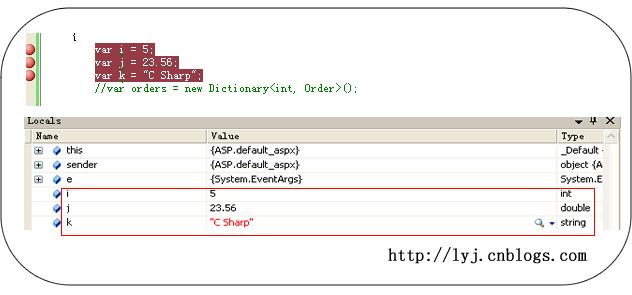
var i = 5;//int var j = 23.56;//double var k = "C Sharp";//string var x;//错误
var y = null;//错误 var z = { 1, 2, 3 };//错误
在调试状态下,编译器解释如下
隐含类型局部变量要点
- var为关键字,可以根据后面的初始化语句自动推断类型,这个类型为强类型。
- 初始化语句必须为表达式,不可以为空。且编译时可以推断类型。一旦初始化之后,只可以存储这种类型。
- var声明的仅限于局部变量,不可用于字段。亦可以用于for,foreach,using 等语句中。
- 数组也可以作为隐含类型。
- 初始化语句不能是一个自身的对象或者集合初始化器,但是他可以是包含一个对象或者初始化器的一个new表达式。
- 如果局部变量声明包含了多个声明符,其类型必须相同。
匿名类型(Anonymous Types)
匿名类型允许定义行内类型,无须显式定义类型。常和var配合使用来声明匿名类型。
var p1 = new { Id = 1, Name = "YJingLee", Age = 22 };
//属性也不需要申明 var p2 = new { Id = 2, Name = "XieQing", Age = 25 }; p1 = p2;//p1,p2结构相同,可以互相赋值
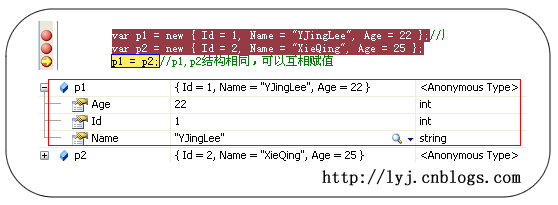
在这里编译器会认为p1,p2相当于:
public class SomeType { public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } }
那么数组怎么定义呢?使用"new[]"关键字来声明数组,加上数组的初始值列表。像这样:
var intArray = new[] { 2, 3, 5, 6 };
var strArray = new[] { "Hello", "World" };
var anonymousTypeArray = new[] { new { Name = "YJingLee", Age = 22 }, new { Name = "XieQing", Age = 25 } };
var a = intArray[0];
var b = strArray[0];
var c = anonymousTypeArray[1].Name;
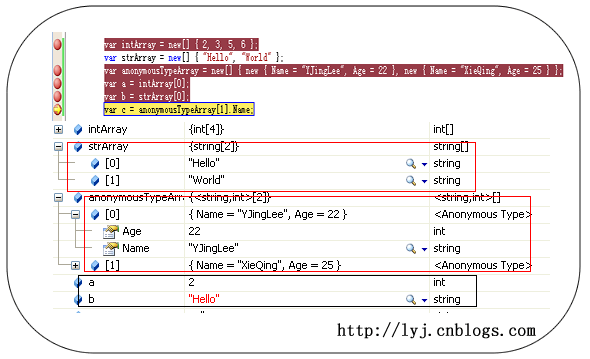
匿名类型要点
- 可以使用new关键字调用匿名初始化器创建一个匿名类型的对象。
- 匿名类型直接继承自System. Object。
- 匿名类型的成员是编译器根据初始化器推断而来的一些读写属性。
对象与集合初始化器(Object and Collection Initializers)
对象初始化器 (Object Initializers) :
.NET2.0框架中的类型非常依赖于属性。当生成对象实例和使用新的类型时,在.Net2.0时候我们像这样写:
User user = new User(); user.Id = 1; user.Name = "YJingLee"; user.Age = 22;
在VS2008中,编译器会自动地生成合适的属性setter代码,使得原来几行的属性赋值操作可以在一行完成。我们可以这样简化:像这样,对象初始化器由一系列成员对象组成,其对象必须初始化,用逗号间隔,使用{}封闭。
User user = new User { Id = 1, Name = "YJingLee", Age = 22 };
又例如,我把二个人加到一个基于泛型的类型为User的List集合中:
List<User> user = new List<User>{ new User{Id=1,Name="YJingLee",Age=22}, new User{Id=2,Name="XieQing",Age=25}, };

如果有相同名字和类型的两个对象初始化器将会产生相同的实例,可以相互赋值。例如:
User user = new User { Id = 1, Name = "YJingLee", Age = 22 };
User user2 = new User { Id = 2, Name = "XieQing", Age = 25 }; user = user2;
除了在初始化类时设置简单的属性值外,对象初始化器特性也允许我们设置更复杂的嵌套(nested)属性类型。例如我们可以在上面定义的User类型同时拥有一个属于Address类型的叫“Address”的属性:
User user = new User { Id = 1, Name = "YJingLee", Age = 22, Address = new Address { City = "NanJing", Zip = 21000 } };
集合初始化器(Collection Initializers):
集合初始化器由一系列集合对象组成,用逗号间隔,使用{}封闭。
集合初始化器可以简化把几个对象一起添加到一个集合,编译器会自动为你做集合插入操作。例如我把七个数加到一个基于泛型的类型为int的List集合中
List<int> num = new List<int> { 0, 1, 2, 6, 7, 8, 9 };
对象与集合初始化器要点
- 对象初始化器实际上利用了编译器对对象中对外可见的字段和属性进行按序赋值。
- 对象初始化器允许只给一部分属性赋值,包括internal访问级别
- 对象初始化器可以结合构造函数一起使用,并且构造函数初始化先于对象初始化器执行。
- 集合初始化器会对初始化器中的元素进行按序调用ICollection<T>.Add(T)方法。
- 注意对象初始化器和集合初始化器中成员的可见性和调用顺序。
- 对象与集合初始化器同样是一种编译时技术。
C# 3.0新语言特性和改进包括:
- 自动属性(Auto-Implemented Properties)
- 隐含类型局部变量(Local Variable Type Inference)
- 匿名类型(Anonymous Types)
- 对象与集合初始化器(Object and Collection Initializers)
- 扩展方法(Extension Methods)
- Lambda表达式和Lambda表达式树 (Lambda Expression and Lambda Expression Trees)
扩展方法(Extension Methods)
往往我们需要对CLR类型进行一些操作,但苦于无法扩展CLR类型的方法,只能创建一些helper方法,或者继承类。我们来修改上面的User类:
public class User{ public int Id { get; set; } public string Name { get; set; } public int Age { get; set; } public string Read() { return "Id:" + Id + "姓名:" + Name + "年龄:" + Age; } }
然后调用
var user = new { Id = 1, Name = "YJingLee", Age = 22 };var str = user.Read();
现在有了扩展方法就方便多了。
扩展方法允许开发人员往一个现有的CLR类型的公开契约(contract)中添加新的方法,而不用生成子类或者重新编译原来的类型。扩展方法有助于把今天动态语言中流行的对duck typing的支持之灵活性,与强类型语言之性能和编译时验证融合起来。——引用Scott博文
扩展方法是可以通过使用实例方法语法调用的静态方法。效果上,使得附加的方法扩展已存在类型和构造类型成为可能。他可以对现有类功能进行扩充,从而使该类型的实例具有更多的方法(功能)。
扩展方法允许我们在不改变源代码的情况下扩展(即添加不能修改)现有类型中的实例方法。
扩展方法给我们一个怎样的思路呢?我们一步一步做一下!
首先声明扩展方法:通过指定关键字this修饰方法的第一个参数。注意扩展方法仅可声明在静态类中。扩展方法具备所有常规静态方法的所有能力,可以使用实例方法语法来调用。接着就可以调用扩展方法了。下面通过一个具体的实例分析一下:
例如我们要检查一个字符串变量是否是合法的电子邮件地址?在.Net2.0框架下像这样:
var email = "leeyongjing@gmail.com";if (EmailValidator.IsValid(email)) { Response.Write("YJingLee提示:这是一个正确的邮件地址"); }
而使用扩展方法的话,我可以添加“IsValidEmailAddress()”方法到string类本身中去,该方法返回当前字符串实例是否是个合法的字符串。
if (email.IsValidEmailAddress()) { Response.Write("YJingLee提示:这是一个正确的邮件地址"); }
我们是怎么把这个IsValidEmailAddress()方法添加到现有的string类里去的呢?先定义一个静态类,再定义“IsValidEmailAddress”这个静态的法来实现的。
public static class Extensions//静态类{ public static bool IsValidEmailAddress(this string s) //静态方法和this { Regex regex = new Regex(@"^[\w-\.]+@([\w-]+\.)+[\w-]{2,4}$"); return regex.IsMatch(s); } }
注意,上面的静态方法在第一个类型是string的参数变量前有个“this”关键词,这告诉编译器,这个特定的扩展方法应该添加到类型为“string”的对象中去。然后在IsValidEmailAddress()方法实现里,我可以访问调用该方法的实际string实例的所有公开属性/方法/事件,取决于它是否是合法电子邮件地址来返回true/false。
扩展方法不仅能够应用到个别类型上,也能应用到.NET框架中任何基类或接口上。即可用于整个.NET框架丰富的可组合的框架层扩展。
扩展方法要点
- 扩展方法的本质为将实例方法调用在编译期改变为静态类中的静态方法调用。事实上,它确实拥有静态方法所具有的所有功能。
- 扩展方法的作用域是整个namespace可见的,并且可以通过using namespace来导入其它命名空间中的扩展方法。
- 扩展方法的优先级:现有实例方法优先级最高,其次为最近的namespace下的静态类的静态方法,最后为较远的namespace下的静态类的静态方法。
- 扩展方法是一种编译时技术,注意与反射等运行时技术进行区别,并慎重使用。
Lambda表达式和Lambda表达式树 (Lambda Expression and Lambda Expression Trees)
Lambda表达式
我们从“所有字符串查找包含YJingLee子字符串”说起。在C# 2.0中,匿名方法允许我们以内联的方式来实现委托实例,它提供强大的函数式编程语言,但是标记显得相当的冗长和带有强制性。我们使用C# 2.0 中的匿名方法查找,代码如下:
var inString = list.FindAll(delegate(string s) { return s.Indexof("YJingLee") >= 0; });
现在可以使用C# 3.0带来的Lambda表达式允许我们使用一种更接近人的思维、更自然的方式来实现类似于匿名方法同样的效果,看下面的代码多么简洁:
var inString = list.FindAll(s => s.Indexof("YJingLee") >= 0);
Lambda表达式格式:(参数列表)=>表达式或语句块
具体意义:定义Lambda接受参数列表,运行表达式或语句块返回表达式或语句块的值传给这个参数列表。
Lambda表达式参数类型可以是隐式类型或显式类型。在显式列表中,每个参数的类型是显式指定的,在隐式列表中,参数的类型由Lambda表达式出现的语境自动推断类型。
Lambda表达式的参数列表可以有一个或多个参数,或者无参数。在有单一的隐型参数的lambda表达式中,圆括号可以从参数列表中省略。
例如:
(x, y) => x * y;//多参数,隐式类型=>表达式x => x * 10;
//单参数,隐式类型=>表达式x => { return x * 10; };
//单参数,隐式类型=>语句块(int x) => x * 10;
//单参数,显式类型=>表达式(int x) => { return x * 10; };
//单参数,显式类型=>语句块() => Console.WriteLine(); //无参数
下面看这个例子:
在前面的帖子中,我们写了一个User类及增加了2个人,接下来,我们使用由LINQ提供的新的Where和Average方法来返回集合中的人的一个子集,以及计算这个集合中的人的平均年龄:
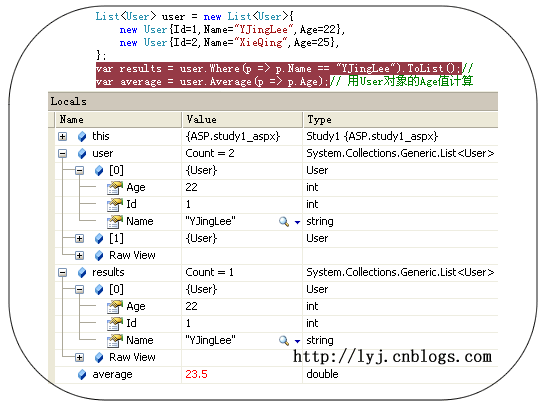
List<User> user = new List<User>{ new User{Id=1,Name="YJingLee",Age=22}, new User{Id=2,Name="XieQing",Age=25}, };//获取特定人时所用的过滤条件,p参数属于User类型
var results = user.Where(p => p.Name == "YJingLee").ToList();
//用User对象的Age值计算平均年龄
var average = user.Average(p => p.Age);
效果图如下:
对这个Lambda表达式做个简要分析:
var resultsdelegate = user.Where(delegate(User p) { return p.Name == "YJingLee";// 返回一个布尔值});
var averagedelegate = user.Average(delegate(User p) { return p.Age; });

Lambda表达式L可以被转换为委托类型D,需要满足以下条件:
L的参数类型要与D的参数个数相等,类型相同,返回类型相同,无论是表达式,还是语句块。注意隐式类型要参与类型辨析。
Lambda表达式树
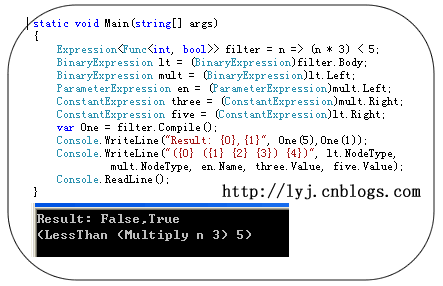
Lambda表达式树允许我们像处理数据(比如读取,修改)一样来处理Lambda表达式。我以一个例子简单说明:
Expression<Func<int, bool>> filter = n => (n * 3) < 5;
BinaryExpression lt = (BinaryExpression)filter.Body;
BinaryExpression mult = (BinaryExpression)lt.Left;
ParameterExpression en = (ParameterExpression)mult.Left;
ConstantExpression three = (ConstantExpression)mult.Right;
ConstantExpression five = (ConstantExpression)lt.Right;
var One = filter.Compile();Console.WriteLine("Result: {0},{1}", One(5), One(1));
Console.WriteLine("({0} ({1} {2} {3}) {4})", lt.NodeType,
mult.NodeType, en.Name, three.Value, five.Value);
效果图如下:
Lambda表达式和Lambda表达式树要点
- Lambda表达式的参数类型可以忽略,因为可以根据使用的上下文进行推断。
- Lambda表达式的主体(body)可以是表达式,也可以是语句块。
- Lambda表达式传入的实参将参与类型推断,以及方法重载辨析。
- Lambda表达式和表达式体可以被转换为表达式树。
- 表达式树允许lambda表达式能够代表数据结构替代表示为执行代码。
好了,我在这里简单的把C# 3.0新语言特性和改进说了一下,接下来,正式进入这个系列的主题部分——LINQ。为 了让大家了解,我换一种手法来写,从一条一条LINQ to SQL语句分析来贯穿LINQ的知识点。一起体验LINQ带给我们的乐趣。

 set beginDir
set beginDir