nginx+php+memcache+xcache+mysql安装与配置
笔记:犹
链接:http://hi.baidu.com/avyou/blog/item/3ed08350f94516898c5430a9.html
安装系统的程序库-->安装数据库-->php需要的支持库-->安装php-->安装php扩展(memcache,xcache)-->安装nginx.
1.安装系统的程序库
yum -y install gcc gcc-c++ autoconf libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel libxml2 libxml2-devel zlib zlib-devel glibc glibc-devel glib2 glib2-devel bzip2 bzip2-devel ncurses ncurses-devel curl curl-devel
一般的,如果安装系统时选择了系统的开发库,只要再安装以下三个包就可以了,gd包也可以用rpm 安装,但gd-devel所依赖的其它包太多,所以后面将用源码包安装.
# rpm -ivh freetype-devel-2.2.1-19.el5.i386.rpm
# rpm -ivh libpng-devel-1.2.10-7.0.2.i386.rpm
# rpm -ivh libjpeg-devel-6b-37.i386.rpm
------------------------------------------------------------------------------
2.安装mysql数据库
为了方便,这里选择rpm包来安装.
# rpm -ivh perl-DBD-MySQL-3.0007-1.fc6.i386.rpm
# rpm -ivh mysql-server-5.0.22-2.1.0.1.i386.rpm
# rpm -ivh mysql-devel-5.0.22-2.1.0.1.i386.rpm //编译安装的php需要的mysql库
# /etc/rc.d/init.d/mysqld start
# mysqladmin -u root -p password yourpass
-------------------------------------------------------------------
3.编译安装PHP 5.2.6所需的支持库:
3.1. 安装libiconv
# tar zxvf libiconv-1.12.tar.gz
# cd libiconv-1.12/
# ./configure --prefix=/usr/local
# make && make install
-------------------------------------------------
3.2. 安装libmcrypt
# tar zxvf libmcrypt-2.5.8.tar.gz
# cd libmcrypt-2.5.8/
# ./configure
# make && make install
# ldconfig
# cd libltdl/
# ./configure --enable-ltdl-install
# make && make install
-------------------------------------------------
3.3.安装mhash
# tar zxvf mhash-0.9.9.tar.gz
# cd mhash-0.9.9/
# ./configure
# make && make install
# cp /usr/local/lib/libmcrypt.* /usr/lib
# ln -s /usr/local/lib/libmhash.so.2 /usr/lib/libmhash.so.2
# ldconfig
-----------------------------------------------------
3.4.安装mcrypt
# tar zxvf mcrypt-2.6.7.tar.gz
# cd mcrypt-2.6.7/
# ./configure
# make && make install
----------------------------------------------------
3.5.安装gd
# tar xvf gd-2.0.32.tar.tar
# cd gd2.0.32
# ./configure
# make && make install
--------------------------------------------------------------------
4.安装php(FastCGI模式)
说明:php-fpm-是 php-5.26的一个fpm管理补丁,在启用FastCGI模式时,可以平滑变更php.ini配置而无需重启php-cgi。没有php5.0 的php-fpm补丁包
# tar zxvf php-5.26.tar.gz
# gzip -cd php-5.2.6-fpm-0.5.8.diff.gz | patch -d php-5.2.6 -p1
# cd php-5.2.6/
# ./configure \
--prefix=/usr/local/php5 \ //php的安装路径
--with-mysql \ //与mysql库相关联
--with-iconv-dir=/usr/local \ //这里的路径要以前面libconv编译包一致
--with-freetype-dir \
--with-jpeg-dir \
--with-png-dir \
--with-zlib
--with-libxml-dir \
--with-gd \
--with-openssl \
--with-mcrypt \
--with-gd \
--enable-gd-native-ttf \
--enable-xml \
--enable-fastcgi \ //启用fastcgi模式
--enable-fpm \ //启用fpm管理
--enable-force-cgi-redirect \
--enable-mbstring \
--enable-inline-optimization \
--disable-debug
# make
# make install
# cp php.ini-dist /usr/local/php5/lib/php.ini
5.安装php5扩展模块
说明:
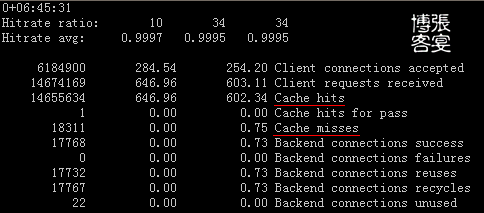
.Memcached是一个高性能的分布式的内存对象缓存系统。本文中的memcache.so是Memcached的客户端PHP扩展,与Xcache、eaccelerator、APC不是同一类东西,没有本质的联系。
.XCache 是一个开源的 opcode 缓存器/优化器, 这意味着他能够提高您服务器上的 PHP 性能. 他通过把编译 PHP 后的数据缓冲到共享内存从而避免重复的编译过程, 能够直接使用缓冲区已编译的代码从而提高速度. 通常能够提高您的页面生成速率 2 到5 倍, 降低服务器负载。eaccelerator、APC 也是 opcode 缓存器/优化器,跟xcache的功能类似,不能跟xcache一起使用。
.xcache还有数据缓存功能,功能跟Memcache类似,但效果不如Memcached。
--------------------------------------------------------------------------------------------
5.1 安装 memcache-2.23.tgz
# tar zxvf memcache-2.23.tgz
# /usr/local/php5/bin/phpize //生成Api版本号,Zend Module Api 号和Zend Extension Api号
#./configure --with-php-config=/usr/local/php5/bin/php-config
# make && make install //生成smemcache.so的路径:/usr/local/php5/lib/php/extensions/no-debug-non-zts-20060613/
--------------------------------------------------------------
5.2 安装xcache-1.2.2.tar.gz
# tar zxvf xcache-1.2.2.tar.gz
# cd xcache-1.2.2
# /usr/local/php5/bin/phpize
# ./configure --with-php-config=/usr/local/php5/bin/php-config --enable-xcache
# make && make install //生成xcache.so的路径:/usr/local/php5/lib/php/extensions/no-debug-non-zts-20060613/
--------------------------------------------------------------------------------------------
6.配置php5扩展模块
6.1 配置memcache
# vi /usr/local/php5/lib/php.ini
;/usr/local/webserver/php/etc/php.ini中的extension_dir = "./" //修改模块路径
/usr/local/webserver/php/etc/php.ini中的extension_dir = "/usr/local/php5/lib/php/extensions/no-debug-non-zts-20060613/"
extension = "memcache.so" //添加memcache.so模块
;display_errors = On
display_errors = Off //修改显示错误为off
---------------------------------------------------------
6.2 配置xcache
# vi xcache-1.2.2/xcache.ini
[xcache-common]
zend_extension = /usr/local/php5/lib/php/extensions/no-debug-non-zts-20060613/xcache.so
[xcache.admin]
xcache.admin.enable_auth = On //启用xcache管理认证
xcache.admin.user = "xcache" //验证名
; xcache.admin.pass = md5($your_password)
xcache.admin.pass = "e10adc3949ba59abbe56e057f20f883e" //md5 后的验证密码, 亦即 md5(您的密码), 留空则禁用管理页面.
[xcache]
xcache.shm_scheme = "mmap" // 选择低级别的共享存储器/分配算符安排执行
xcache.size = 32M //0 禁止, 非 0 则启用缓存器. 请注意您系统所允许的 mmap 最大值.
xcache.count = 1 //指定将 cache 切分成多少块. 参考 SplittedCache,可以用(cat /proc/cpuinfo |grep -c processor)命令查看
xcache.slots = 8K // 只是作为 hash 槽个数的参考值, 您可以放心地缓冲超过这个个数的项目
xcache.ttl = 0 //设置缓冲项目的 Ttl (Time To Live) 值, 0=永不过期
xcache.gc_interval = 0 //检查过期项目, 回收内存空间的间隔.
//同上, 不过用于数据缓冲而不是 opcode 缓冲.
xcache.var_size = 2M
xcache.var_count = 1
xcache.var_slots = 8K
xcache.var_ttl = 0
xcache.var_maxttl = 0
xcache.var_gc_interval = 300
xcache.test = Off
xcache.readonly_protection = Off
xcache.mmap_path = "/dev/zero" //对于 *nix, xcache.mmap_path 是 文件路径, 不是目录.
;xcache.cacher = On
;xcache.stat = On
;xcache.optimizer = On //启用优化器 (目前无效).
# cp xcache-1.2.2/xcache.ini /usr/local/php5/etc/xcache.ini
# cat /usr/local/php5/etc/xcache.ini >> /usr/local/php5/lib/php.ini
---------------------------------------------------------------------------------------------------------
6.3 安装xcache的web管理界面
说明:这一步留到安装完成nginx后来再来做,写在这里只为了顺着xcache的流程
# vi /var/data/www/md.php //获取md密码,在浏览器输入http://192.168.1.5/md.php,显示e10adc3949ba59abbe56e057f20f883e,得到后删除.
<?php
echo md5("password");
?>
--------------------------------
# rm -rf /var/data/www/md.php
# vi /usr/local/php5/lib/php.ini //修改php.ini文件
xcache.admin.user = "xcache"
xcache.admin.pass = "e10adc3949ba59abbe56e057f20f883e"
# cp -a xcache/admin /var/data/www/xcache
# chown -R www:www /var/data/www/xcache
# chmod -R +x /var/data/xcache
-------------------------------------------------------------------------
7.创建nginx的用户和组,并给虚拟主机目录分配权限
# groupadd www -g 101
# useradd -u 101 -g www www -s /bin/false
# mkdir -p /var/data/www/error
# chmod 755 /var/data/www
# chown -R www:www /var/data/www
---------------------------------------------------------------------
8.修改php-fpm配置文件,启动php-cgi进程
# vi /usr/local/php5/etc/php-fpm.conf //这里主要做几处修改即可,记得去掉里面的注释,否则启动出错!
--> <value name="pid_file">/usr/local/php5/logs/php-fpm.pid</value>
--> <value name="error_log">/usr/local/php5/logs/php-fpm.log</value>
--> <value name="user">www</value>
--> <value name="group">www</value>
--> <value name="max_children">25</value>
--> <value name="MaxSpareServers">35</value>
--> <value name="rlimit_files">10240</value>
--> <value name="max_requests">10240</value>
# ulimit -SHn 10240
# /usr/local/php5/sbin/php-fpm start //参数start|stop|quit|restart|reload|logrotate
-------------------------------------------------------------
9.安装与配置nginx
说明:
.gzip 模块需要 zlib 库
.rewrite 模块需要 pcre 库
.ssl 功能需要 openssl 库
----------------------------
9.1 安装pcre库
# tar zxvf pcre-7.7.tar.gz
# cd pcre-7.7/
# ./configure
# make && make install
-----------------------------------
9.2 安装nginx
# tar zxvf nginx-0.6.31.tar.gz
# cd nginx-0.6.31/
# ./configure --user=www --group=www --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module
# make && make install
-----------------------------------------
9.3 配置nginx
# mkdir /var/log/nginx
# chmod +w /var/log/nginx
# chown -R www:www /var/log/nginx
# cd /usr/local/nginx/conf
# cp nginx.conf nginx.conf.bak
# vi nginx.conf
-------------------------------------------------------------------------------------------------
user www www;
worker_processes 1;
error_log /var/log/nginx/error.log crit;
pid /var/log/nginx/nginx.pid;
events {
use epoll; //规定使用的I/O复用模式,Linux 2.6内核的epoll,FreeBSD用kqueue
worker_connections 2048;
}
http {
include mime.types;
default_type application/octet-stream;
keepalive_timeout 60;
sendfile on;
tcp_nopush on; //allows or forbids socket options TCP_NOPUSH on FreeBSD or TCP_CORK on Linux.
This option is only available when using sendfile.
tcp_nodelay on; //This directive allows or forbids the use of the socket option TCP_NODELAY. Only included in keep-alive connections.
fastcgi_connect_timeout 60;
fastcgi_send_timeout 180;
fastcgi_read_timeout 180;
fastcgi_buffer_size 128k;
fastcgi_buffers 4128k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 128k;
fastcgi_temp_path /dev/shm;
gzip on;
gzip_min_length 1k;
gzip_buffers 48k;
gzip_http_version 1.1;
gzip_types text/plain application/x-javascript text/css text/html application/xml;
server {
listen 80;
server_name localhost;
index index.php index.html index.htm;
root /var/data/www;
charset utf8,gb2312;
log_format main '$remote_addr - $remote_user [$time_local] $request '
'"$status" $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
if (-d $request_filename){ //如果在浏览中输入"http://xxx/yy"会在目录yy后面加上"/"即"http://xxx/yy/"
rewrite ^/(.*)([^/])$ http://$host/$1$2/ permanent;
}
location ~ .*\.php?$ { //matches any request ending in .php?
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
}
error_page 404 http://192.168.1.5/error/404.html;
error_page 500 502 503 504 http://192.168.1.5/error/50x.html;
server {
listen 5200;
server_name localhost;
allow 192.168.1.101/32;
deny all;
location / {
root /var/www2/xcache;
index index.html index.htm;
}
location ~ .*\.php?$ {
root /var/www2/xcache;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index index.php;
include fastcgi.conf;
}
}
# server {
# listen 192.168.1.5;
# listen 192.168.1.5:80;
# server_name www.test3.com;
# location / {
# root /var/data/www3;
# index index.html index.htm;
# }
#
# }
}
---------------------------------------------------
# vi /usr/local/nginx/conf/fastcgi.conf //fastcgi的配置文件需要它,nginx才能支持php.也可以对fastcgi_params 进行简单修改
#fastcgi.conf
fastcgi_param GATEWAY_INTERFACE CGI/1.1;
fastcgi_param SERVER_SOFTWARE nginx;
fastcgi_param QUERY_STRING $query_string;
fastcgi_param REQUEST_METHOD $request_method;
fastcgi_param CONTENT_TYPE $content_type;
fastcgi_param CONTENT_LENGTH $content_length;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param SCRIPT_NAME $fastcgi_script_name;
fastcgi_param REQUEST_URI $request_uri;
fastcgi_param DOCUMENT_URI $document_uri;
fastcgi_param DOCUMENT_ROOT $document_root;
fastcgi_param SERVER_PROTOCOL $server_protocol;
fastcgi_param REMOTE_ADDR $remote_addr;
fastcgi_param REMOTE_PORT $remote_port;
fastcgi_param SERVER_ADDR $server_addr;
fastcgi_param SERVER_PORT $server_port;
fastcgi_param SERVER_NAME $server_name;
# PHP only, required if PHP was built with --enable-force-cgi-redirect
#fastcgi_param REDIRECT_STATUS 200;
--------------------------------------------------------------------------------------------------------------------------------
10.管理web服务
10.1管理命令
# /usr/local/php5/sbin/php-fmp restart
# /usr/local/nginx/sbin/nginx -t //测试配置文件,-c指定配置文件路径,-v显示 nginx 的版本,-V 显示 nginx 的版本,编译器版本和配置参数。
# /usr/local/nginx/sbin/nginx //启动nginx
# ps aux | grep '(PID|nginx)' //显示nginx的PID号2213
# kill -HUP 2213 //不用重启nginx,直接重新加载配置
# kill -HUP /var/log/nginx/nginx.pid //或者更新nginx.pid
------------------------------------------------------------------------
说明:
首先,使用新的可执行程序替换旧的,然后,发送USR2(kill –USR2 ROOT_PID)信号给主进程,主进程将重新命名它的.pid文件为nginx.pid..oldbin,然后执行新的可执行程序,依次启动新的主进程和工作进程。在这时,两个nginx实例会同时运行,一起处理输入的请求。需要逐步停止旧的实例,此时需要发送WINCH信号给就的主进程,然后它的工作进程开始关闭。一段时间后,旧的工作进程处理了所有已连接的请求后退出,就仅由新的工作进程来处理输入的请求。这时,因为旧的服务器还尚未关闭它监听的套接字,所以通过下面几步仍然可以恢复旧的服务器。
. 发送 HUP 信号给旧的主进程 - 它将在不重载配置文件的情况下启动它的工作进程
. 发送 QUIT 信号给新的主进程,要求其从容关闭其工作进程
. 发送 TERM 信号给新的主进程,迫使其退出
. 如果因为某些原因新的工作进程不能退出,向其发送 KILL 信号
------------------------------------------------------------------------
10.2管理日志
# vi /usr/local/nginx/sbin/nginxlog //日志截断脚本
#!/bin/sh
# This file run at 00:00
logdate=$(date -d "yesterday" +"%Y-%m-%d") //昨天的年月日
logdir=/var/log/nginx
gzip -c ${logdir}/access.log>${logdir}/${logdate}.log.gz
------------------------------------------------------
# echo ""> ${logdate}/access.log
# chmod +x /var/local/nginx/sbin/nginxlog
# crontab -e
0 0 * * * /usr/local/nginx/sbin/nginxlog>>/dev/null 2>&1