
简介
该篇blog只是存储系列科普文章中的第二篇,所有文章请参考:
在工程架构领域里,存储是一个非常重要的方向,这个方向从底至上,我分成了如下几个层次来介绍:
- 硬件层:讲解磁盘,SSD,SAS, NAS, RAID等硬件层的基本原理,以及其为操作系统提供的存储界面;
- 操作系统层:即文件系统,操作系统如何将各个硬件管理并对上提供更高层次接口;
- 单机引擎层:常见存储系统对应单机引擎原理大概介绍,利用文件系统接口提供更高级别的存储系统接口;
- 分布式层:如何将多个单机引擎组合成一个分布式存储系统;
- 查询层:用户典型的查询语义表达以及解析;
文件系统磁盘分配
在存储知识栈上提到文件系统, 大家首先就关心他是如何管理好硬件层提供的磁盘空间的。
本文开篇就先描述典型的几种文件系统管理磁盘的技术方案: 连续分配, 链式分配, 索引分配。
连续分配
顾名思义, 就是创建文件的时候, 给分配一组连续的块。在单独拿出一块地方存储各个文件的meta信息, meta信息也很简单, 包含文件名, 起始位置和长度即可, 这个存放meta信息的地方也叫做FAT(文档分配表)。
如下图:
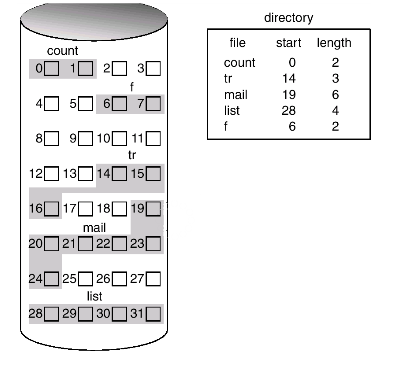
该方案的优点:
- 简便, 适用于一次性写入操作;
- 所需磁盘寻道次数和寻道时间最少;
缺点也很明显:
- 文件不能动态增长, 因为后面的块可能已经分配给别人了;
- 不利于文件的插入和删除, 插入文件之前需要声明文件大小;
- 外部碎片问题;
为了克服连续分配的问题, 又进化出来了链式分配方案。
链式分配
链式分配即将文件块像链表一样管理起来, 每个块中放一个指针, 指针指向下一个文件块所在的位置。这样在FAT中存储也很简单, 只需要存储文件名, 起始块号和结束块号(都可以不存)。
如下图:
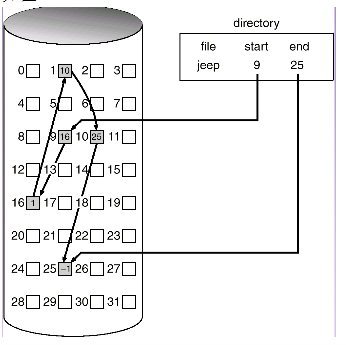
该方案的优点:
- 提高磁盘利用率, 没有碎片问题
- 有利于文件的插入, 删除
缺点:
- 存取速度慢, 需要移动的磁道次数多, 寻道时间长;
- 读写任何一个地方都需要沿着指针前进直到找到对应块为止;
- 链接占据了一定的磁盘空间, 数据不是严格按照块大小分配;
索引分配
这是一个折衷方案, 也是现在大部分文件系统采用的方案, 他综合了连续分配和链式分配的好处。
该方案会在FAT中保存所有文件块的位置, 各文件系统都有一套自己对应的细节分配策略, 会保证一个文件尽量连续的同时, 又避免出现大量的磁盘碎片。
如下图:
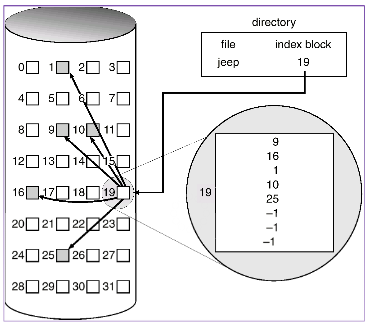
该方案的优点是:
- 能够保持好大部分文件的局部性
- 满足文件插入, 删除的高效
- 随机读写不需要沿着指针前进
缺点:
- 会有较多的磁盘寻道次数
- 索引表本身管理复杂, 也会带来额外的系统开销
ext文件系统
基本概念
- 块. 即Block, 数据存储的最小单元, 每个块都有一个唯一的地址, 从0开始, 起源于第一个可以用来存储数据的扇区;
- 超级块. 超级块保存了各种文件系统的meta信息, 比如块大小信息。他位于文件系统的2号和3号扇区(物理地址), 占用两个扇区大小;
- 块组. 所有的块会划分成多个块组, 每个块组包含同样多个块, 但是可能整个文件系统整个块数不是块组的整数倍, 所以最后一个块组包含的个数可能会小于其他块;
总体结构
一个ext文件系统分成多个块组, 每个块组的结构基本相同, 如下:
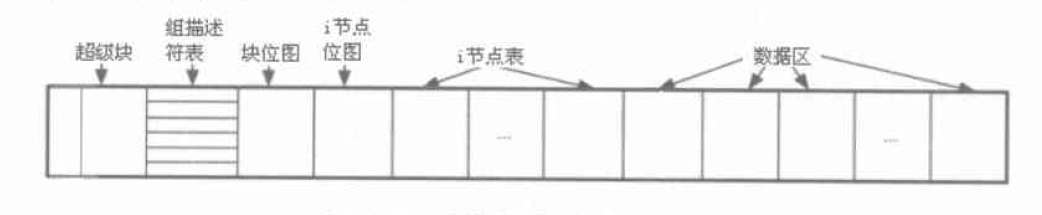
解释如下:
- 0~1号扇区: 引导扇区. 如果没有引导代码, 则这两个扇区为空, 全部用0填充;
- 2~3号扇区: 超级块, 超级块包含各种meta信息:
- 块大小, 每个块组包含块数, 总块数, 第一个块前保留块数, inode节点数, 每个块组的inode节点数
- 卷名, 最后挂载时间, 挂载路径, 文件系统是否干净, 是否要调用一致性检查标识
- 空间inode节点和空闲块的记录信息, 在分配inode节点和新块的时候使用
- 组描述符表:
位于超级块后面的一个块, 注意在超级块之前只占用了4个扇区, 如果一个块大小超过4个扇区的话, 这里就会有空的扇区。
组描述符表中包含了所有块组的描述信息, 每个块组占据32个字节(差不多是8个整数的大小)。如果格式化使用默认参数, 那么组描述符表不会超过一块块组。
组描述符和超级块在每个块组中都有一个备份, 但是激活了
稀疏超级块特征的情况除外。稀疏超级块即不是在所有块组中都存储超级块和组描述符的备份, 默认该策略被激活, 其策略类似当块组号是3,5,7的幂的块组才存副本。 - 块位图表
每个块对应一个bit, 只包含了本块组的信息。而文件系统创建的时候, 默认每个块组包含的块数跟每个块包含的bit数是一样的, 这种情况下每个块位图表正好等于一个块的大小。
而该位图表的块的起始位置会在组描述符表中指定, 大小则为块组中包含块数个bit。
- inode位图块
跟块位图表类似, 通常情况他也只占用一个块。通常一个块组中的inode节点数会小于block数量, 所以其不会超过一个块大小。
- inode节点表
每个inode都占用128位的一个描述信息, 起始位置在组描述符中表示, 大小为inode节点数*128。
- 数据区
这就是真正存储数据的区域。
块大小为4096的时候, 各部分和扇区对应关系如下图:
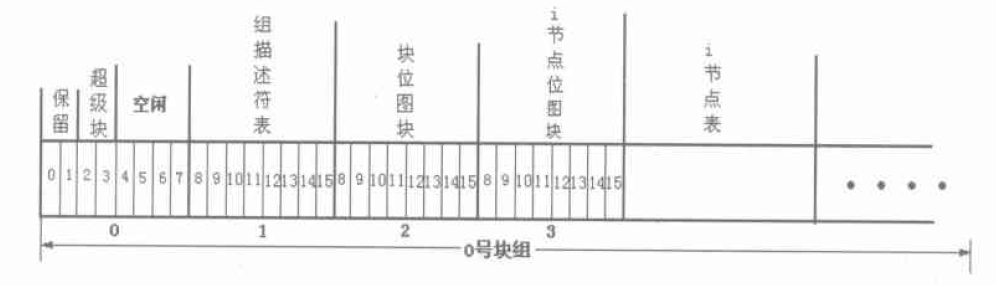
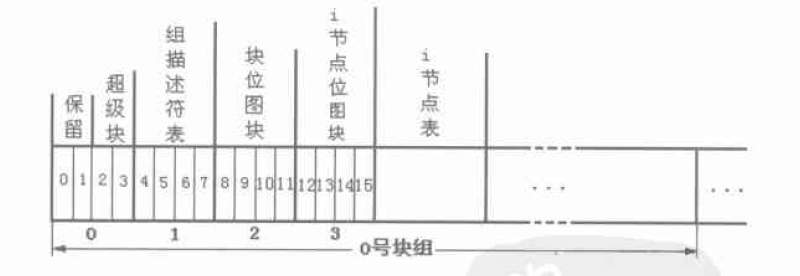
块大小为2048的时候, 各部分和扇区对应关系如下图:
超级块详细信息
超级块总是位于文件系统的第1024~2048字节处。
超级块中包含的信息如下:
| 偏移(16进制) | 字节数 | 含义&解释 |
|---|---|---|
| 00~03 | 4 | 文件系统中总inode节点数 |
| 04~07 | 4 | 文件系统中总块数 |
| 08~0B | 4 | 为文件系统预保留的块数 |
| 0C~0F | 4 | 空闲块数 |
| 10~13 | 4 | 空间inode节点数 |
| 14~17 | 4 | 0号块组起始块号 |
| 18~1B | 4 | 块大小(1024左移位数) |
| 1C~1F | 4 | 片段大小, 跟块大小一模一样 |
| 20~23 | 4 | 每个块组中包含的块数量 |
| 24~27 | 4 | 每个块组中包含的片段数量, 跟包含的快数量一致 |
| 28~2B | 4 | 每个块组中包含的inode节点数量 |
| 2C~2F | 4 | 文件系统最后挂载时间 |
| 30~33 | 4 | 文件系统最后写入时间 |
| 34~35 | 2 | 当前挂载数 |
| 36~37 | 2 | 最大挂载数 |
| 38~39 | 2 | 文件系统签名标识 53EF |
| 3A~3B | 2 | 文件系统状态, 正常, 错误, 恢复了孤立的inode节点 |
| 3C~3D | 2 | 错误处理方式, 继续, 以只读方式挂载 |
| 3E~3F | 2 | 辅版本号 |
| 40~43 | 4 | 最后进行一致性检查的时间 |
| 44~47 | 4 | 一致性检查的间隔时间 |
| 48~4B | 4 | 创建本文件系统的操作系统 |
| 4C~4F | 4 | 主版本号, 只有该值为1的时候, 偏移54之后的扩展超级块的一些动态属性值才是有意义的 |
| 50~51 | 2 | 默认为UID的保留块 |
| 52~53 | 2 | 默认为GID的保留块 |
| 54~57 | 2 | 第一个非保留的inode节点号, 即用户可以使用的第一个inode节点号 |
| 58~59 | 2 | 每个inode节点的大小字节数 |
| 5A~5B | 2 | 本超级块所在的块组号 |
| 5C~5F | 4 | 兼容标识特征 |
| 60~63 | 4 | 非兼容标识特征 |
| 64~67 | 4 | 只读兼容特征标识 |
| 68~77 | 16 | 文件系统ID号 |
| 78~87 | 16 | 卷名 |
| 88~C7 | 64 | 最后的挂载路径 |
| C8~CB | 4 | 位图使用的运算法则 |
| CC~CC | 1 | 文件再分配的块数 |
| CD~CD | 1 | 目录再分配的块数 |
| CE~CF | 2 | 未使用 |
| D0~DF | 16 | 日志ID |
| E0~E3 | 4 | 日志inode节点 |
| E4~E7 | 4 | 日志设备 |
| E8~EB | 4 | 孤立的inode节点表 |
| EC~3FF | 788 | 未使用 |
块组描述符详细信息
每个块组描述符占用32个字节, 其数据结构如下:
| 偏移(16进制) | 字节数 | 含义&解释 |
|---|---|---|
| 00~03 | 4 | 块位图起始地址(块号) |
| 04~07 | 4 | inode节点位图起始地址(块号) |
| 08~0B | 4 | inode节点表起始地址(块号) |
| 0C~0D | 2 | 块组中空闲块数 |
| 0E~0F | 2 | 块组中空闲inode节点数 |
| 10~11 | 2 | 块组中的目录数 |
| 12~1F | - | 未使用 |
inode信息
每个inode会被分配给一个目录或者一个文件, 每个inode包含了128个字节, 里面包含了这个文件的各种meta信息。
在所有inode中, 1~10号会用作保留给内核使用, 在这些保留节点中, 2号节点用于存储根目录信息, 1号表示坏块, 8号表示日志文件信息。
第一个用户可见的都是从11号inode开始, 11号节点一般用作lost+found目录, 当检查程序发现一个inode节点已经被分配, 但是没有文件名指向他的时候, 就会把他添加到lost+found目录中并赋予一个新的文件名。
inode通过三级指针的方式来找到文件数据最终存储的数据块, 见下图:
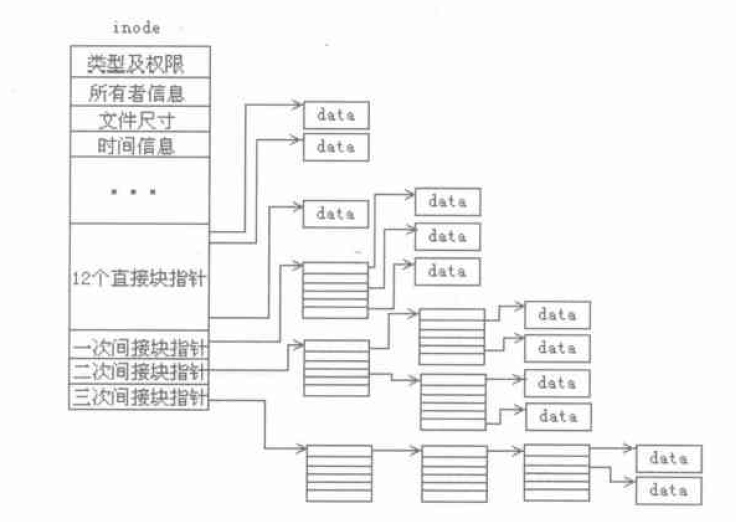
这种方式能保证小文件的读取效率的同时, 也支持大文件的读取。
目录项
在ext文件系统中, 每个目录也对应一个inode节点, 该inode节点对应的数据块里面会存储该目录下所有文件/目录的信息。
每个文件/目录对应的信息就叫目录项, 目录项包含的内容也很简单, 主要就是文件名和指向该文件名的inode指针, 详细信息如下:
| 偏移(16进制) | 字节数 | 含义&解释 |
|---|---|---|
| 00~03 | 4 | inode节点号 |
| 04~05 | 2 | 本目录项的长度字节数 |
| 06~06 | 1 | 名字长度字节数 |
| 07~07 | 1 | 文件类型 |
| 08~ | 不定长度 | 名字的ascii码 |
当文件删除的时候, 不会真正删除文件, 会将该文件所属目录对应的目录项给删除, 同时将对应数据块在快位图表中标记为0。
链接
- 硬链接是指在另外一个目录对应的目录项中增加一个目录项。硬链接建立之后, 用户无法通过文件名来判断到底哪个是原文件名, 哪个是链接名;
- 软连接是一种文件类型, 该文件里面就存储源文件的完整路径, 如果源文件完整路径长度小于60个字节, 那么就将该值直接存储在inode节点表中, 避免浪费数据块;
分配策略
- 首先判断应该在哪个块组中分配
- 如果是为文件创建节点
- 默认会在其父目录所在的组中为其创建节点, 这样可以确保一个目录中所有文件都位于一个大致的区域中
- 如果父目录所在组没有空闲的节点或者空闲的块了, 就到别的块组中为该文件分配节点, 找寻别的块组的算法如下
- 每次讲当前组号加上2^N次方再求hash
- 如果上面的算法没找到, 就线性查找
- 如果是为目录创建节点
- 会将其分配到可用空间较多的块组中, 分配算法如下:
- 首先利用超级块中的剩余inode和剩余块数字算出每个块组的平均剩余数字, 然后依次找到一个大于平均值的块组
- 如果没找到, 就利用块组描述符表中的信息, 找到一个最空闲的块组
- 会将其分配到可用空间较多的块组中, 分配算法如下:
- 如果是为文件创建节点
- 当一个数据块分配给某文件之后
- 该块原来的内容会被请出, inode节点对应的各种元信息会跟着做修改
- 如果是文件, 节点对应链接数会设置为1, 如果是目录, 链接数会被设置为2
实际创建/删除文件过程
我们创建一个/xuanku/file.txt, 该文件大小为10000字节, 文件块大小为4096, 那么下面来看一下过程:
- 读取文件系统的1024字节~2048字节, 即超级块信息。通过超级块得到快大小为4096, 每个块组含有8192个块以及2008个inode节点
- 读取文件系统中第1个块(即组描述符表), 得到所有块组布局信息
- 访问2号inode节点(即根节点), 通过读取根节点数据块信息, 假设读到其位于5号块
- 在第5号块所有目录项中从前往后遍历, 直到找到文件名为
xuanku的目录项, 读到该inode节点为4724 - 每个块组有2008个inode, 用4724针对2008取模, 得到的结果是2号块组
- 通过组描述符表中得到第2个块组的inode节点表起始于16378号块
- 从16378号块读取inode节点表中查找4724号对应的inode节点(708号表项), 查询到该
xuanku的目录内容位于17216号块 - 从17216块读取
xuanku目录项内容, 将file.txt相关信息更新到该块的目录项当中 - 然后开始为文件分配inode节点, 默认会放到父目录所在块组, 即2号块组, 再次2号块组的inode节点表16378, 开始从4724往后找到第一个可用的inode节点分配给该文件, 假设找到的是4850号inode。
- 然后就给4850号的inode位图表设置为1, 组描述符的空闲inode节点数和超级块的总空闲inode节点数都减1, 将inode节点的地址写入
file.txt对应的目录项当中, 然后写各种时间, 记录日志 - file.txt需要3个块的存储空间, 通过2号块组描述符找到块位图对应的块, 并从前往后找到可用的块。然后将对应的位设置为1, 并更新到inode节点当中
- 然后将文件的内容写入到对应的块中
下面再演示一下将该文件删除的过程:
- 读取文件系统的1024字节~2048字节, 即超级块信息。通过超级块得到快大小为4096, 每个块组含有8192个块以及2008个inode节点
- 读取文件系统中第1个块(即组描述符表), 得到所有块组布局信息
- 访问2号inode节点(即根节点), 通过读取根节点数据块信息, 假设读到其位于5号块
- 在第5号块所有目录项中从前往后遍历, 直到找到文件名为
xuanku的目录项, 读到该inode节点为4724 - 每个块组有2008个inode, 用4724针对2008取模, 得到的结果是2号块组
- 通过组描述符表中得到第2个块组的inode节点表起始于16378号块
- 从16378号块读取inode节点表中查找4724号对应的inode节点(708号表项), 查询到该
xuanku的目录内容位于17216号块 - 从17216块读取
xuanku目录项内容, 读到file.txt的inode节点为4850 - 然后取消
file.txt的目录项分配, 修改系列xuanku目录对应的目录项信息 - 取消inode节点信息, 修改2号块组对应的inode节点表信息, 将inode节点位设置为0, 更新块组描述符和超级块的空闲inode节点数加1
- 还要回收文件内容对应的6个块空间, 将块位图表中的bit设置为0, 清除inode节点的块指针, 更新块组描述符和超级块的空闲块数加1
参考
- 数据重新 文件系统原理精解与数据恢复最佳实践
- 磁盘分配方式. http://blog.csdn.net/liuqiyao_01/article/details/39156651
- ext在线调整大小. http://www.ibm.com/developerworks/cn/linux/l-cn-ext4resize/