所谓事务性,本多指数据库的属性,包括ACID四个基本要素:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
我们这里主要讨论隔离性,Lucene的IndexReader和IndexWriter具有隔离性。
- 当IndexReader.open打开一个索引的时候,相对于给当前索引进行了一次snapshot,此后的任何修改都不会被看到。
- 仅当IndexReader.open打开一个索引后,才有可能看到从上次打开后对索引的修改。
- 当IndexWriter没有调用Commit的时候,其修改的内容是不能够被看到的,哪怕IndexReader被重新打开。
- 欲使最新的修改被看到,一方面IndexWriter需要commit,一方面IndexReader重新打开。
下面我们举几个例子来说明上述隔离性:
|
(1) 首先做准备,索引十篇文档 File indexDir = new File("TestIsolation/index"); IndexWriter writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); for(int i =0; i < 10; i++){ indexDocs(writer); } writer.close(); (2) 然后再索引十篇文档,并不commit writer = new IndexWriter(FSDirectory.open(indexDir), new StandardAnalyzer(Version.LUCENE_CURRENT), IndexWriter.MaxFieldLength.LIMITED); for(int i =0; i < 10; i++){ indexDocs(writer); } (3) 打开一个IndexReader,但是由于IndexWriter没有commit,所以仍然仅看到十篇文档。 IndexReader reader = IndexReader.open(FSDirectory.open(indexDir)); IndexSearcher searcher = new IndexSearcher(reader); TopDocs docs = searcher.search(new TermQuery(new Term("contents","hello")), 50); System.out.println(docs.totalHits); (4) IndexWriter进行提交commit writer.commit(); (5) 不重新打开IndexReader,进行搜索,仍然仅看到十篇文档。 docs = searcher.search(new TermQuery(new Term("contents","hello")), 50); System.out.println(docs.totalHits); (6) IndexReader重新打开,则可以看到二十篇文档。 reader = IndexReader.open(FSDirectory.open(indexDir)); searcher = new IndexSearcher(reader); docs = searcher.search(new TermQuery(new Term("contents","hello")), 50); System.out.println(docs.totalHits); |
由于前一章所述的Lucene的事务性,使得Lucene可以增量的添加一个段,我们知道,倒排索引是有一定的格式的,而这个格式一旦写入是非常难以改变的,那么如何能够增量建索引呢?Lucene使用段这个概念解决了这个问题,对于每个已经生成的段,其倒排索引结构不会再改变,而增量添加的文档添加到新的段中,段之间在一定的时刻进行合并,从而形成新的倒排索引结构。
然而也正因为Lucene的事务性,使得Lucene的索引不够实时,如果想Lucene实时,则必须新添加的文档后IndexWriter需要commit,在搜索的时候IndexReader需要重新的打开,然而当索引在硬盘上的时候,尤其是索引非常大的时候,IndexWriter的commit操作和IndexReader的open操作都是非常慢的,根本达不到实时性的需要。
好在Lucene提供了RAMDirectory,也即内存中的索引,能够很快的commit和open,然而又存在如果索引很大,内存中不能够放下的问题。
所以要构建实时的索引,就需要内存中的索引RAMDirectory和硬盘上的索引FSDirectory相互配合来解决问题。
1、初始化阶段
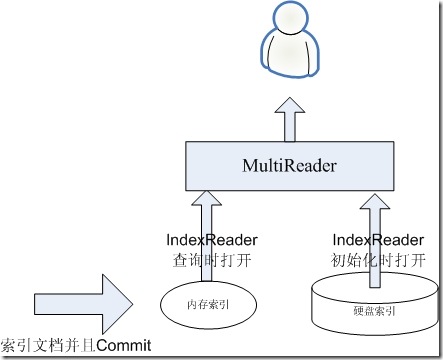
首先假设我们硬盘上已经有一个索引FileSystemIndex,由于IndexReader打开此索引非常的慢,因而其是需要事先打开的,并且不会时常的重新打开。
我们在内存中有一个索引MemoryIndex,新来的文档全部索引到内存索引中,并且是索引完IndexWriter就commit,IndexReader就重新打开,这两个操作时非常快的。
如下图,则此时新索引的文档全部能被用户看到,达到实时的目的。
2、合并索引阶段
然而经过一段时间,内存中的索引会比较大了,如果不合并到硬盘上,则可能造成内存不够用,则需要进行合并的过程。
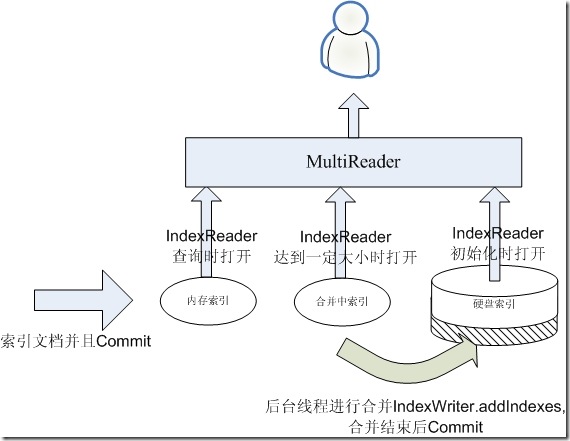
当然在合并的过程中,我们依然想让我们的搜索是实时的,这是就需要一个过渡的索引,我们称为MergingIndex。
一旦内存索引达到一定的程度,则我们重新建立一个空的内存索引,用于合并阶段索引新的文档,然后将原来的内存索引称为合并中索引,并启动一个后台线程进行合并的操作。
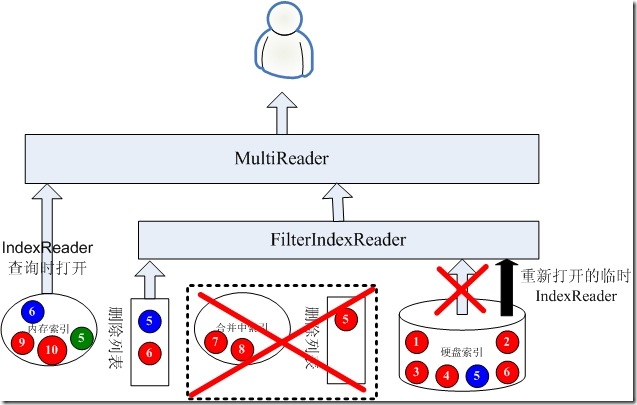
在合并的过程中,如果有查询过来,则需要三个IndexReader,一个是内存索引的IndexReader打开,这个过程是很快的,一个是合并中索引的IndexReader打开,这个过程也是很快的,一个是已经打开的硬盘索引的IndexReader,无需重新打开。这三个IndexReader可以覆盖所有的文档,唯一有可能重复的是,硬盘索引中已经有一些从合并中索引合并过去的文档了,然而不用担心,根据Lucene的事务性,在硬盘索引的IndexReader没有重新打开的情况下,背后的合并操作它是看不到的,因而这三个IndexReader所看到的文档应该是既不少也不多。合并使用IndexWriter(硬盘索引).addIndexes(IndexReader(合并中索引)),合并结束后Commit。
如下图:
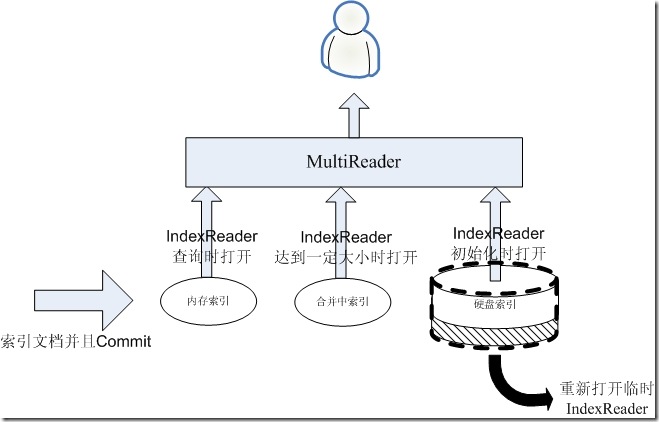
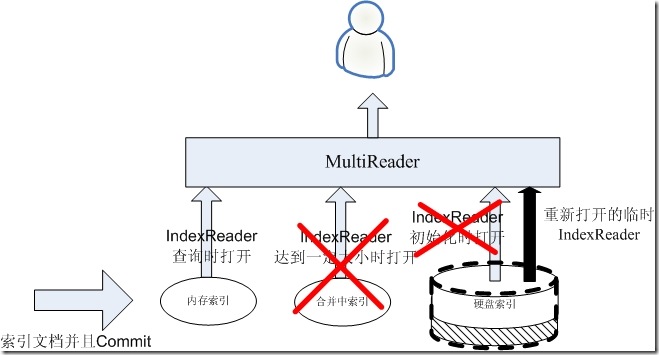
3、重新打开硬盘索引的IndexReader
当合并结束后,是应该重新打开硬盘索引的时候了,然而这是一个可能比较慢的过程,在此过程中,我们仍然想保持实时性,因而在此过程中,合并中的索引不能丢弃,硬盘索引的IndexReader也不要动,而是为硬盘索引打开一个临时的IndexReader,在打开的过程中,如果有搜索进来,返回的仍然是上述的三个IndexReader,仍能够不多不少的看到所有的文档,而将要打开的临时的IndexReader将能看到合并中索引和原来的硬盘索引所有的文档,此IndexReader并不返回给客户。如下图:
4、替代IndexReader
当临时的IndexReader被打开的时候,其看到的是合并中索引的IndexReader和硬盘索引原来的IndexReader之和,下面要做的是:
(1) 关闭合并中索引的IndexReader
(2) 抛弃合并中索引
(3) 用临时的IndexReader替换硬盘索引原来的IndexReader
(4) 关闭硬盘索引原来的IndexReader。
上面说的这几个操作必须是原子性的,如果做了(2)但没有做(3),如果来一个搜索,则将少看到一部分数据,如果做了(3)没有做(2)则,多看到一部分数据。
所以在进行上述四步操作的时候,需要加一个锁,如果这个时候有搜索进来的时候,或者在完全没有做的时候得到所有的IndexReader,或者在完全做好的时候得到所有的IndexReader,这时此搜索可能被block,但是没有关系,这四步是非常快的,丝毫不影响替代性。
如下图:
经过这几个过程,又达到了第一步的状态,则进行下一个合并的过程。
5、多个索引
有一点需要注意的是,在上述的合并过程中,新添加的文档是始终添加到内存索引中的,如果存在如下的情况,索引速度实在太快,在合并过程没有完成的时候,内存索引又满了,或者硬盘上的索引实在太大,合并和重新打开要花费太长的时间,使得内存索引以及满的情况下,还没有合并完成。
为了处理这种情况,我们可以拥有多个合并中的索引,多个硬盘上的索引,如下图:
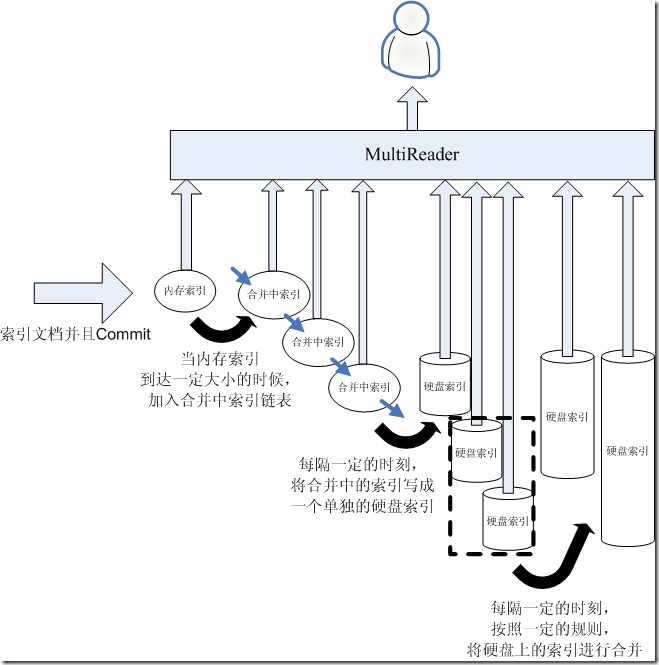
- 新添加的文档永远是进入内存索引
- 当内存索引到达一定的大小的时候,将其加入合并中索引链表
- 有一个后台线程,每隔一定的时刻,将合并中索引写入一个新的硬盘索引中取。这样可以避免由于硬盘索引过大而合并较慢的情况。硬盘索引的IndexReader也是写完并重新打开后才替换合并中索引的IndexReader,新的硬盘索引也可保证打开的过程不会花费太长时间。
- 这样会造成硬盘索引很多,所以,每隔一定的时刻,将硬盘索引合并成一个大的索引。也是合并完成后方才替换IndexReader
大家可能会发现,此合并的过程和Lucene的段的合并很相似。然而Lucene的一个函数IndexReader.reopen一直是没有实现的,也即我们不能选择哪个段是在内存中的,可以被打开,哪些是硬盘中的,需要在后台打开然后进行替换,而IndexReader.open是会打开所有的内存中的和硬盘上的索引,因而会很慢,从而降低了实时性。
在有关Lucene的问题(7),讨论了使用Lucene内存索引和硬盘索引构建实时索引的问题。
然而有的读者提到,如果涉及到文档的删除及更新,那么如何构建实时的索引呢?本节来讨论这个问题。
1、Lucene删除文档的几种方式
- IndexReader.deleteDocument(int docID)是用 IndexReader 按文档号删除。
- IndexReader.deleteDocuments(Term term)是用 IndexReader 删除包含此词(Term)的文档。
- IndexWriter.deleteDocuments(Term term)是用 IndexWriter 删除包含此词(Term)的文档。
- IndexWriter.deleteDocuments(Term[] terms)是用 IndexWriter 删除包含这些词(Term)的文档。
- IndexWriter.deleteDocuments(Query query)是用 IndexWriter 删除能满足此查询(Query)的文档。
- IndexWriter.deleteDocuments(Query[] queries)是用 IndexWriter 删除能满足这些查询(Query)的文档。
删除文档既可以用reader进行删除,也可以用writer进行删除,不同的是,reader进行删除后,此reader马上能够生效,而用writer删除后,会被缓存,只有写入到索引文件中,当reader再次打开的时候,才能够看到。
2、Lucene文档更新的几个问题
2.1、使用IndexReader还是IndexWriter进行删除
既然IndexReader和IndexWriter都能够进行文档删除,那么到底是应该用哪个来进行删除呢?
本文的建议是,用IndexWriter来进行删除。
因为用IndexReader可能存在以下的问题:
(1) 当有一个IndexWriter打开的时候,IndexReader的删除操作是不能够进行的,否则会报LockObtainFailedException
(2) 当IndexReader被多个线程使用的时候,一个线程用其进行删除,会使得另一个线程看到的索引有所改变,使得另一个线程的结果带有不确定性。
(3) 对于更新操作,在Lucene中是先删除,再添加的,然而删除的被立刻看到的,而添加却不能够立刻看到,造成了数据的不一致性。
(4) 即便以上问题可以通过锁来解决,然而背后的操作影响到了搜索的速度,是我们不想看到的。
2.2、如何在内存中缓存文档的删除
在上一节中,为了能够做到实时性,我们使用内存中的索引,而硬盘上的索引则不经常打开,即便打开也在背后线程中打开。
而要删除的文档如果在硬盘索引中,如果不重新打开则看不到新的删除,则需要将删除的文档缓存到内存中。
那如何将缓存在内存中的文档删除在不重新打开IndexReader的情况下应用于硬盘上的索引呢?
在Lucene中,有一种IndexReader为FilterIndexReader,可以对一个IndexReader进行封装,我们可以实现一个自己的FilterIndexReader来过滤掉删除的文档。
一个例子如下:
|
public class MyFilterIndexReader extends FilterIndexReader { OpenBitSet dels; public MyFilterIndexReader(IndexReader in) { super(in); dels = new OpenBitSet(in.maxDoc()); } public MyFilterIndexReader(IndexReader in, List<String> idToDelete) throws IOException { super(in); dels = new OpenBitSet(in.maxDoc()); for(String id : idToDelete){ TermDocs td = in.termDocs(new Term("id", id)); //如果能在内存中Cache从Lucene的ID到应用的ID的映射,Reader的生成将快得多。 if(td.next()){ dels.set(td.doc()); } } } @Override public int numDocs() { return in.numDocs() - (int) dels.cardinality(); } @Override public TermDocs termDocs(Term term) throws IOException { return new FilterTermDocs(in.termDocs(term)) { @Override public boolean next() throws IOException { boolean res; while ((res = super.next())) { if (!dels.get(doc())) { break; } } return res; } }; } @Override public TermDocs termDocs() throws IOException { return new FilterTermDocs(in.termDocs()) { @Override public boolean next() throws IOException { boolean res; while ((res = super.next())) { if (!dels.get(doc())) { break; } } return res; } }; } } |
2.3、文档更新的顺序性问题
Lucene的文档更新其实是删除旧的文档,然后添加新的文档。如上所述,删除的文档是缓存在内存中的,并通过FilterIndexReader应用于硬盘上的索引,然而新的文档也是以相同的id加入到索引中去的,这就需要保证缓存的删除不会将新的文档也过滤掉,将缓存的删除合并到索引中的时候不会将新的文档也删除掉。
Lucene的两次更新一定要后一次覆盖前一次,而不能让前一次覆盖后一次。
所以内存中已经硬盘中的多个索引是要被保持一个顺序的,哪个是老的索引,哪个是新的索引,缓存的删除自然是应该应用于所有比他老的索引的,而不应该应用于他自己以及比他新的索引。
3、具有更新功能的Lucene实时索引方案
3.1、初始化
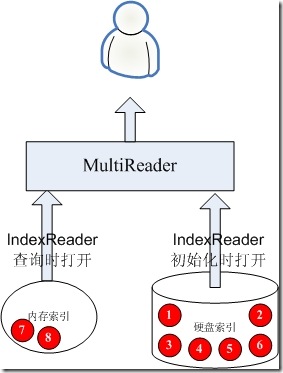
首先假设我们硬盘上已经有一个索引FileSystemIndex,被事先打开的,其中包含文档1,2,3,4,5,6。
我们在内存中有一个索引MemoryIndex,新来的文档全部索引到内存索引中,并且是索引完IndexWriter就commit,IndexReader就重新打开,其中包含文档7,8。
3.2、更新文档5
这时候来一个新的更新文档5, 需要首先将文档5删除,然后加入新的文档5。
需要做的事情是:
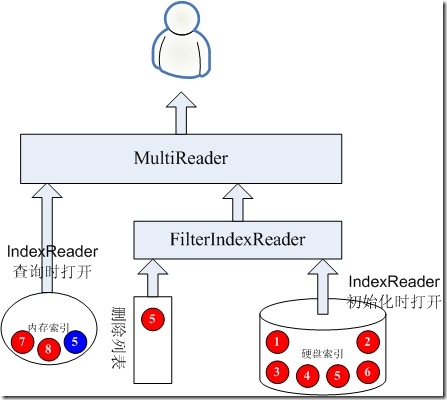
- 首先在内存索引中删除文档5,当然没有文档5,删除无效。
- 其次将对文档5的删除放入内存文档删除列表,并与硬盘的IndexReader组成FilterIndexReader
- 最后,将新的文档5加入内存索引,这时候,用户可以看到的就是新的文档5了。
- 将文档5放入删除列表以及将文档5提交到内存索引两者应该是一个原子操作,好在这两者都是比较块的。
注:此处对硬盘上的索引,也可以进行对文档5的删除,由于IndexReader没有重新打开,此删除是删不掉的,我们之所以没有这样做,是想保持此次更新要么全部在内存中,要么全部在硬盘中,而非删除部分已经应用到硬盘中,而新文档却在内存中,此时,如果系统crash,则新的文档5丢失了,而旧的文档5也已经在硬盘上被删除。我们将硬盘上对文档5的删除放到从内存索引向硬盘索引的合并过程。
如果再有一次对文档5的更新,则首先将内存索引中的文档5删除,添加新的文档5,然后将文档5加入删除列表,发现已经存在,则不必删除。
3.3、合并索引
然而经过一段时间,内存中的索引需要合并到硬盘上。
在合并的过程中,需要重新建立一个空的内存索引,用于合并阶段索引新的文档,而合并中的索引的IndexReader以及硬盘索引和删除列表所组成的FilterIndexReader仍然保持打开,对外提供服务,而合并阶段从后台进行。
后台的合并包括以下几步:
- 将删除列表应用到硬盘索引中。
- 将内存索引合并到硬盘索引中。
- IndexWriter提交。
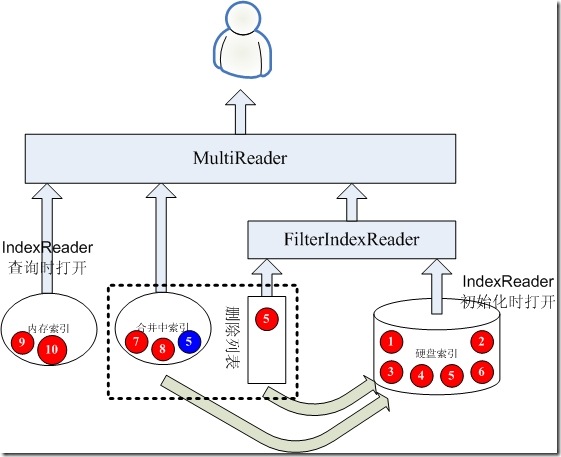
3.4、合并的过程中更新文档5
在合并的过程中,如果还有更新那怎么办呢?
- 首先将合并中索引的文档5删除,此删除不会影响合并,因为合并之前,合并中索引的IndexReader已经打开,索引合并中索引的文档5还是会合并到硬盘中去的。此删除影响的是此后的查询在合并中索引是看不到文档5的。
- 然后将文档5的删除放入删除列表,并同合并中索引的删除列表,已经硬盘索引一起构成FilterIndexReader。
- 将新的文档5添加到内存中索引。
- 提交在合并中索引对文档5的删除,将文档5添加到删除列表,提交在内存索引中对文档5的添加三者应该是一个原子操作,好在三者也是很快的。
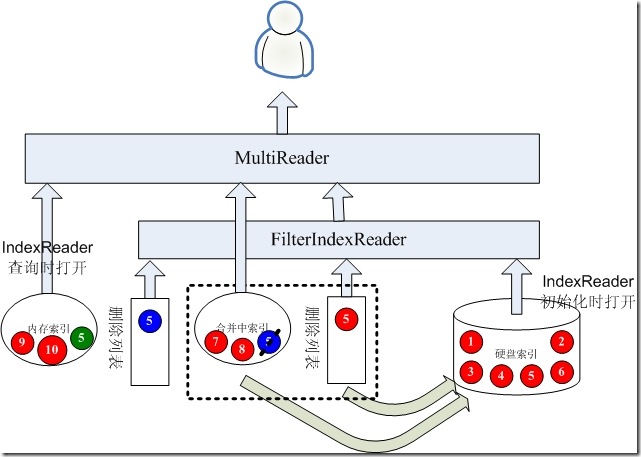
3.5、重新打开硬盘索引的IndexReader
当合并中索引合并到硬盘中的时候,是时候重新打开硬盘上的索引了,新打开的IndexReader是可以看到文档5的删除的。
如果这个时候有新的更新,也是添加到内存索引和删除列表的,比如我们更新文档6.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
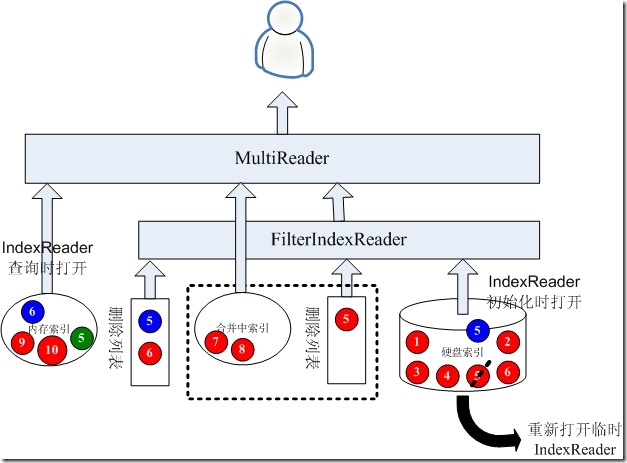
3.6、替代IndexReader
当IndexReader被重新打开后,则需要删除合并中的索引及其删除列表,将硬盘索引原来的IndexReader关闭,使用新的IndexReader。
{kind=link}