下载:
http://download.gluster.org/pub/gluster/glusterfs/
Fuse支持库安装
查看发Fuse是否已经安装:
命令:
#lsmod | grep "fuse"
如果显示:
fuse 66285 4
系统已经安装Fuse,跳过次安装步骤,进入下个软件的安装,否则继续下面的安装
文件: "fuse-2.8.4.tar.gz"
解压
#tar -xzvf fuse-2.8.4.tar.gz
#cd fuse-2.8.4 (进入目录,下述命令需要在该目录下执行)
安装编译:
#./configure --prefix=/usr (设定安装目录)
#make
#make install
挂载fuse内核模块
#modprobe fuse (关键)
#lsmod | grep "fuse" (查询fuse内核模块是否已正确挂载)
1.1.2 GlusterFs安装
检查GlusterFs是否已经安装:
命令:gluster –V 或 glusterfs -V
如果显示:
glusterfs 3.2.5 built on Mar 7 2012 16:10:28
Repository revision: git://git.gluster.com/glusterfs.git
Copyright (c) 2006-2011 Gluster Inc. <http://www.gluster.com>
GlusterFS comes with ABSOLUTELY NO WARRANTY.
You may redistribute copies of GlusterFS under the terms of the GNU General Public License.
GlusterFs已经安装,跳过此安装步骤,否则继续下面的安装
文件: " glusterfs-3.2.5.tar.gz"
解压
#tar -xzvf glusterfs-3.2.5.tar.gz
#cd glusterfs-3.2.5 (进入目录,下述命令需要在该目录下执行)
安装编译:
#./configure --prefix=/usr (设定安装目录)
#make
#make install
查看是否安装成功:
命令:gluster –V 或 glusterfs -V
如果显示:
glusterfs 3.2.5 built on Mar 7 2012 16:10:28
Repository revision: git://git.gluster.com/glusterfs.git
Copyright (c) 2006-2011 Gluster Inc. <http://www.gluster.com>
GlusterFS comes with ABSOLUTELY NO WARRANTY.
You may redistribute copies of GlusterFS under the terms of the GNU General Public License.
则安装成功
1.1.3 启动glusterd
# /etc/init.d/glusterd start
显示:
Starting glusterd:[ OK ]
启动成功
首先,依次登陆各个服务器启动glusterd;并将每个服务器对应的多个ip信息,添加到配置文件中,以d182服务器为例:(假设集群是由四个服务器节点构成)
登陆d182服务器
vi /etc/hosts
把如下信息写入hosts 文件
192.168.1.182 d182
192.168.1.172 d182
192.168.1.162 d182
192.168.1.183 d183
192.168.1.173 d183
192.168.1.163 d183
192.168.1.184 d184
192.168.1.174 d184
192.168.1.164 d184
192.168.1.185 d185
192.168.1.175 d185
192.168.1.165 d185
在服务器d183、d184、d185上都添加上诉信息。(上面的例子是每个服务器对应3个ip,共4个服务器,总计12条记录)
创建GlusterFS集群:
$ gluster peer probe SERVER
SERVER表示存储服务器的hostname。例如要创建包含四台服务器的GlusterFS集群使用命令如下:(在d182 服务器上输入)
# gluster peer probe d183
# gluster peer probe d184
# gluster peer probe d185
注意:在构建GlusterFS集群时,需要在其中任意一台存储服务器上依次将其他存储服务器添加到集群中。
添加完集群之后,登陆集群中的其他服务器,例:从d182登陆d183
查看集群信息指令:
gluster peer status
显示信息如下:
Number of Peers: 3
Hostname: 192.168.1.182
Uuid: f97d4478-9374-41b9-b296-fb9840ff1a42
State: Peer in Cluster (Connected)
Hostname: d184
Uuid: 503d8c85-03c5-40be-8bbe-f19419f3d985
State: Peer in Cluster (Connected)
Hostname: d185
Uuid: 3697827c-23e5-4238-9f8c-10c1a920bcdb
State: Peer in Cluster (Connected)
显示红色字体”Connected”,为集群节点添加成功,但其中d182是以192.168.1.182这个ip加入集群的,需要换成hostname
登陆集群中的集群中的另一个节点:
例:登陆d183服务器
执行指令:
gluster peer detach 192.168.1.182
gluster peer probe d182
集群节点添加完毕
指令:gluster volume create test-volume replica 2 transport tcp server1:/exp1
server2:/exp2 server3:/exp3 server4:/exp4
test-volume:创建的逻辑卷的名字
replica 2: 冗余数
server1: 服务器名
exp1: brick的路径
查看volume 信息:# gluster volume info
1.3启动卷
启动卷命令:
# gluster volume start v8
V8为创建的逻辑卷的名字。
客户端挂载存储服务器卷使用:
如果本机在节点群里面,那就使用本机的服务,如 127.0.0.1:/test-vol,如果本机不在集群节点里面,就得使用任何一个节点服务器的服务。
如: localhost:/v8
mount -t glusterfs d182:/v8 /usr/local/movies
d182表示主host name
V8表示卷名
/usr/local/movies表示客户端挂载点
验证mount是否成功:
$ df –h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 128G 33G 89G 28% /
/dev/sda1 1.9G 42M 1.8G 3% /boot
tmpfs 2.0G 0 2.0G 0% /dev/shm
glusterfs#182:/v8
551G 1.4G 521G 1% /usr/local/movies
出现红色字体部分表示已经挂载上存储服务器。
节点故障处理
如果一台节点服务器down机,这个时候,我们要恢复故障,替换volume中坏掉的brick为新的brick,参考如下操作:
#prob server
gluster peer probe [new-server]
#replace old to new brick
gluster volume replace-brick vol-name [old-server]:/[old-brick] [new-server]:/[new-brick] start
#检查同步的状态
gluster volume replace-brick vol-name [old-server]:/[old-brick] [new-server]:/[new-brick] status
#等待同步完成之后 提交
gluster volume replace-brick vol-name [old-server]:/[old-brick] [new-server]:/[new-brick] commit force
只需在一台节点上操作,所有的服务器上该卷的brick都换成新的brick了
---------------------------------------------------------------------------------
GlusterFS分布式集群文件系统安装、配置及性能测试
前几天和天涯的刘天斯在讨论分布式文件系统,才想起电脑内还有一篇一年前写的文档,现在帖在这里,给有需要的朋友看看,因为当时是用word写的,帖在这边排版不是很好。大家凑合着看吧。
1. 版本历史
Revision Author(s) Date Summary of activity
1.0 罗辉 2009-6-1 创建本文档
2. 参考文档
[1] http:// www.gluster.org
[2] http://wenzizone.cn/?p=8
3. 前言
Glusterfs是一个具有可以扩展到几个PB数量级的分布式集群文件系统。它可以把多个不同类型的存储块通过Infiniband RDMA或者TCP/IP汇聚成一个大的并行网络文件系统。
考虑到公司图片服务器后期的升级,我们对Glusterfs进行了比较详细的技术测试。
4. 测试环境
我们采用八台老的至强服务器组成了测试环境,配置为内存1-2G不等,每台有两块以上的73G SCSI硬盘。
同时每服务器配有两块网卡,连接至两个100M以太网交换机上。192.168.1.x段连接的是cisco 2950,另一个段是一个d-link交换机,服务器间的传输主要是通过cisco 2950,以保证网络的稳定性。
IP地址分别为:192.168.1.11~192.168.1.18 及 192.168.190.11~192.168.190~18。
所有服务器的操作系统都是Centos linux 5.3,安装DAG RPM Repository的更新包。DAG RPM Repository下载页面为:http://dag.wieers.com/rpm/packages/rpmforge-release/。
安装方式:
# wget http://dag.wieers.com/rpm/packages/rpmforge-release/rpmforge-release-0.3.6-1.el5.rf.i386.rpm
# rpm –ivh rpmforge-release-0.3.6-1.el5.rf.i386.rpm
5. GlusterFS的安装
5.1. 服务器端安装
我们通过rpm编译方式来安装GlusterFS,因为做为群集文件系统,可能需要在至少10台以上的服务器上安装GlusterFS。每台去源码编译安装太费功夫,缺乏效率。在一台编译为rpm包,再复制到其它的服务器上安装是最好的选择。
GlusterFS需要fuse支持库,需先安装:
# yum -y install fuse fuse-devel httpd-devel libibverbs-devel
下载GlusterFS源码编译rpm包。
# wget http://ftp.gluster.com/pub/gluster/glusterfs/2.0/LATEST/glusterfs-2.0.0.tar.gz
# tar -xvzf glusterfs-2.0.0.tar.gz
# cp glusterfs-2.0.0.tar.gz /usr/src/redhat/SOURCES/
# rpmbuild -bb glusterfs-2.0.0/glusterfs.spec
# cp /usr/src/redhat/RPMS/i386/glusterfs* .
# rm glusterfs-debuginfo-2.0.0-1.i386.rpm
# rpm -ivh glusterfs-*.rpm
安装完成,并把编译好的rpm包复制到其它服务器上安装。
5.2. 客户端安装
客户端和服务器有一点点不同,特别需要注意的是在客户端这边,不但需要fuse库,并且需要一个fuse内核模块。好在DAG RPM Repository内已有用DKMS方式编译好的内核模块包,我们直接安装便可。
DKMS(Dynamic Kernel Module Support)是dell发起的一个项目,目的是希望能在不编译内核的情况下,动态的更新内核模块,最重要的是,通过DKMS方式编译的内核模块,由于是由DKMS管理的,在内核升级后,无需重新编译,仍旧可用。这种方式可大大方便以后的内核更新。
GlusterFS可直接用上面rpm编译后的包安装:
# yum -y install dkms dkms-fuse fuse fuse-devel httpd-devel libibverbs-devel
# rpm -ivh glusterfs-*.rpm
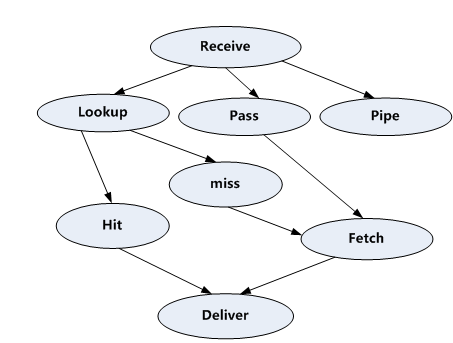
6. GlusterFS的典型架构图
7. GlusterFS常用translators(中继)
7.1.1. storage/posix
type storage/posix
storage/posix的作用是指定一个本地目录给GlusterFS内的一个卷使用。
配置例子:
volume posix-example
type storage/posix
option directory /sda4
end-volume
7.1.2. protocol/server (服务器)
type protocol/server
服务器中继(protocol/server)表示本节点在GlusterFS中为服务器模式。
配置例子:
volume server-example
type protocol/server
option transport-type tcp
subvolumes brick #定义好的卷
option auth.addr.brick.allow * #指定可访问本卷的访问者,*为所有,可对访问者做限制,如192.168.1.*
end-volume
7.1.3. protocol/client (客户端)
type protocol/client
客户端中继(protocol/server)用于客户端连接服务器时使用。
配置例子:
volume client-example
type protocol/client
option transport-type tcp
option remote-host 192.168.1.13 #连接的服务器
option remote-subvolume brick #连接的服务器卷名
end-volume
7.1.4. cluster/replicate(复制)
type cluster/replicate
复制中继(cluster/replicate,前身是AFR)为GlusterFS提供了类似RAID-1的功能。
Replicate会复制文件或者文件夹到各个subvolumes里。如一个卷(volume)内有两个子卷(subvolume),那就会有两份文件或文件夹的复本。
Replicate只时还有高可用的功能,如果两个子卷中有一个子卷挂了,卷依然可以正常工作。当这个子卷重新启用时,会自动更新丢失的文件或文件夹,不过更新是通过客户端进行的。
配置例子:
volume replicate-example
type cluster/replicate
subvolumes brick3 brick4
end-volume
7.1.5. cluster/distribute (分布式)
type cluster/distribute
分布式中继(cluster/distribute,前身是unify)为GlusterFS提供了类似RAID-0的功能。
Distribute可把两个卷或子卷组成一个大卷,实现多存储空间的聚合
配置例子:
volume distribute-example
type cluster/distribute
subvolumes repl1 repl2
end-volume
7.1.6. features/locks (锁)
type features/locks
锁中继(features/locks)只能用于服务器端的posix中继之上,表示给这个卷提供加锁(fcntl locking)的功能。
配置例子:
volume locks-example
type features/locks
subvolumes posix-example
end-volume
7.1.7. performance/read-ahead (预读)
type performance/read-ahead
预读中继(performance/read-ahead)属于性能调整中继的一种,用预读的方式提高读取的性能。
读取操作前就预先抓取数据。这个有利于应用频繁持续性的访问文件,当应用完成当前数据块读取的时候,下一个数据块就已经准备好了。
额外的,预读中继也可以扮演读聚合器,许多小的读操作被绑定起来,当成一个大的读请求发送给服务器。
预读处理有page-size和page-count来定义,page-size定义了,一次预读取的数据块大小,page-count定义的是被预读取的块的数量
不过官方网站上说这个中继在以太网上没有必要,一般都能跑满带宽。主要是在IB-verbs或10G的以太网上用。
配置例子:
volume readahead-example
type performance/read-ahead
option page-size 256 # 每次预读取的数据块大小
option page-count 4 # 每次预读取数据块的数量
option force-atime-update off #是否强制在每次读操作时更新文件的访问时间,不设置这个,访问时间将有些不精确,这个将影响预读转换器读取数据时的那一时刻而不是应用真实读到数据的那一时刻。
subvolumes <x>
end-volume
7.1.8. performance/write-behind (回写)
type performance/write-behind
回写中继(performance/read-ahead)属于性能调整中继的一种,作用是在写数据时,先写入缓存内,再写入硬盘。以提高写入的性能。
回写中继改善了了写操作的延时。它会先把写操作发送到后端存储,同时返回给应用写操作完毕,而实际上写的操作还正在执行。使用后写转换器就可以像流水线一样把写请求持续发送。这个后写操作模块更适合使用在client端,以期减少应用的写延迟。
回写中继同样可以聚合写请求。如果aggregate-size选项设置了的话,当连续的写入大小累积起来达到了设定的值,就通过一个写操作写入到存储上。这个操作模式适合应用在服务器端,以为这个可以在多个文件并行被写入磁盘时降低磁头动作。
配置例子:
volume write-behind-example
type performance/write-behind
option cache-size 3MB # 缓存大小,当累积达到这个值才进行实际的写操作
option flush-behind on # 这个参数调整close()/flush()太多的情况,适用于大量小文件的情况
subvolumes <x>
end-volume
7.1.9. performance/io-threads (IO线程)
type performance/io-threads
IO线程中继(performance/io-threads)属于性能调整中继的一种,作用是增加IO的并发线程,以提高IO性能。
IO线程中继试图增加服务器后台进程对文件元数据读写I/O的处理能力。由于GlusterFS服务是单线程的,使用IO线程转换器可以较大的提高性能。这个转换器最好是被用于服务器端,而且是在服务器协议转换器后面被加载。
IO线程操作会将读和写操作分成不同的线程。同一时刻存在的总线程是恒定的并且是可以配置的。
配置例子:
volume iothreads
type performance/io-threads
option thread-count 32 # 线程使用的数量
subvolumes <x>
end-volume
7.1.10. performance/io-cache (IO缓存)
type performance/io-cache
IO缓存中继(performance/io-threads)属于性能调整中继的一种,作用是缓存住已经被读过的数据,以提高IO性能。
IO缓存中继可以缓存住已经被读过的数据。这个对于多个应用对同一个数据多次访问,并且如果读的操作远远大于写的操作的话是很有用的(比如,IO缓存很适合用于提供web服务的环境,大量的客户端只会进行简单的读取文件的操作,只有很少一部分会去写文件)。
当IO缓存中继检测到有写操作的时候,它就会把相应的文件从缓存中删除。
IO缓存中继会定期的根据文件的修改时间来验证缓存中相应文件的一致性。验证超时时间是可以配置的。
配置例子:
volume iothreads
type performance/ io-cache
option cache-size 32MB #可以缓存的最大数据量
option cache-timeout 1 #验证超时时间,单位秒
option priority *:0 #文件匹配列表及其设置的优先级
subvolumes <x>
end-volume
7.1.11. 其它中继
其它中继还有
cluster/nufa(非均匀文件存取)
cluster/stripe(条带,用于大文件,分块存储在不用服务器)
cluster/ha(集群)
features/filter(过滤)
features/trash(回收站)
path-converter
quota
老的还有:
cluster/unify(和distribute,可定义不同的调度器,以不同方式写入数据)
8. GlusterFS配置
8.1. 服务器端配置
服务器为6台,IP分别是192.168.1.11~192.168.1.16。配置为:
# vi /etc/glusterfs/glusterfsd.vol
volume posix
type storage/posix
option directory /sda4
end-volume
volume locks
type features/locks
subvolumes posix
end-volume
volume brick
type performance/io-threads
option thread-count 8
subvolumes locks
end-volume
volume server
type protocol/server
option transport-type tcp
subvolumes brick
option auth.addr.brick.allow *
end-volume
保存后启动GlusterFS:
# service glusterfsd start
8.2. 客户端配置
服务器为192.168.1.17和192.168.1.18:
# vi /etc/glusterfs/glusterfs.vol
volume brick1
type protocol/client
option transport-type tcp
end-volume
volume brick2
type protocol/client
option transport-type tcp
option remote-host 192.168.1.12
option remote-subvolume brick
end-volume
volume brick3
type protocol/client
option transport-type tcp
option remote-host 192.168.1.13
option remote-subvolume brick
end-volume
volume brick4
type protocol/client
option transport-type tcp
option remote-host 192.168.1.14
option remote-subvolume brick
end-volume
volume brick5
type protocol/client
option transport-type tcp
option remote-host 192.168.1.15
option remote-subvolume brick
end-volume
volume brick6
type protocol/client
option transport-type tcp
option remote-host 192.168.1.16
option remote-subvolume brick
end-volume
volume afr1
type cluster/replicate
subvolumes brick1 brick2
end-volume
volume afr2
type cluster/replicate
subvolumes brick3 brick4
end-volume
volume afr3
type cluster/replicate
subvolumes brick5 brick6
end-volume
volume unify
type cluster/distribute
subvolumes afr1 afr2 afr3
end-volume
GlusterFS的主要配置都在客户端上,上面配置文件的意思是把6台服务器分成3个replicate卷,再用这3个replicate卷做成一个distribute,提供应用程序使用。
8.3. GlusterFS挂载
GlusterFS挂载为在客户端上执行:
# glusterfs -f /etc/glusterfs/glusterfs.vol /gmnt/ -l /var/log/glusterfs/glusterfs.log
-f /etc/glusterfs/glusterfs.vol为指定GlusterFS的配置文件
/gmnt是挂载点
-l /var/log/glusterfs/glusterfs.log为日志
另外,GlusterFS也可以结果fstab或autofs方式开机挂载。挂载后就可以在/gmnt内读写文件了,用法与读写本地硬盘一样。
9. GlusterFS性能测试
9.1. 单客户端测试
测试1:复制大约2.5G容量 /usr目录至GlusterFS(大部分都是小文件)
测试结果:
glusterfs 1361KB/s
本地硬盘 2533KB/s
测试2: 复制一个3.8G的文件至GlusterFS
测试结果:
glusterfs 2270KB/s
本地硬盘 10198KB/s
测试3:读取测试2复制的大文件(cat xxx.iso > /dev/null)
测试结果:
glusterfs 11.2MB/s(基本跑满100M带宽)
本地硬盘 45.6MB/s
9.2. 双客户端测试
测试1:在两个客户端上同时复制大约2.5G容量 /usr目录至GlusterFS(大部分都是小文件)
测试结果:
192.168.1.17:glusterfs 1438KB/s
192.168.1.18:glusterfs 1296KB/s
测试2: 在两个客户端上同时复制一个3.8G的文件至GlusterFS
测试结果:
192.168.1.17:glusterfs 2269KB/s
192.168.1.18:glusterfs 2320KB/s
9.3. 配置回写功能后的测试
9.3.1. 服务器配置
volume posix
type storage/posix
option directory /sda4
end-volume
volume locks
type features/locks
subvolumes posix
end-volume
volume writebehind
type performance/write-behind
option cache-size 16MB
option flush-behind on
subvolumes locks
end-volume
volume brick
type performance/io-threads
option thread-count 64
subvolumes writebehind
end-volume
volume server
type protocol/server
option transport-type tcp
option auth.addr.brick.allow * # Allow access to "brick" volume
end-volume
9.3.2. 客户端配置
volume brick1
type protocol/client
option transport-type tcp
option remote-host 192.168.1.11 # IP address of the remote brick
option remote-subvolume brick # name of the remote volume
end-volume
volume brick2
type protocol/client
option transport-type tcp
option remote-host 192.168.1.12
option remote-subvolume brick
end-volume
volume brick3
type protocol/client
option transport-type tcp
option remote-host 192.168.1.13
option remote-subvolume brick
end-volume
volume brick4
type protocol/client
option transport-type tcp
option remote-host 192.168.1.14
option remote-subvolume brick
end-volume
volume brick5
type protocol/client
option transport-type tcp
option remote-host 192.168.1.15
option remote-subvolume brick
end-volume
volume brick6
type protocol/client
option transport-type tcp
option remote-host 192.168.1.16
option remote-subvolume brick
end-volume
volume afr1
type cluster/replicate
subvolumes brick1 brick2
end-volume
volume afr2
type cluster/replicate
subvolumes brick3 brick4
end-volume
volume afr3
type cluster/replicate
subvolumes brick5 brick6
end-volume
volume wb1
type performance/write-behind
option cache-size 2MB
option flush-behind on
subvolumes afr1
end-volume
volume wb2
type performance/write-behind
option cache-size 2MB
option flush-behind on
subvolumes afr2
end-volume
volume wb3
type performance/write-behind
option cache-size 2MB
option flush-behind on
subvolumes afr3
end-volume
volume unify
type cluster/distribute
subvolumes wb1 wb2 wb3
end-volume
9.3.3. 测试
测试:在两个客户端上同时复制大约2.5G容量 /usr目录至GlusterFS(大部分都是小文件)
测试结果:
192.168.1.17:glusterfs 979KB/s
192.168.1.18:glusterfs 1056KB/s
10. 结语
从测试结果看,小文件的写入速度只有1M多,速度过低,好在在多客户端的情况下,写入速度还算平稳。大文件的写入也只有2M。对于做图片服务器来说,只能算勉强够用。
另外在性能调优方面,在我们加上回写后,速度反而有下降。当然也有可能是配置参数不当的原因。
经测试,GlusterFS在高可用方面比较稳定的,基本能达到要求。不过由于在复制模式的更新是通过客户端进行的,当客户端和replicate内的一台服务器同时挂时,会造成数据不同步的情况。需要手动做个列表的动作(ls)才会更新。
GlusterFS作为正式运营环境使用时,还缺乏一些功能,如GlusterFS没有对整个集群的监控和管理程序等。
--------------------------------------------------------------------------
一些命令配置
1.在一台服务器上建立Distributed Volume
假设服务器为:192.168.113.173(Server)
假设客户端为:192.168.113.179(Client)
首先配置Server,开启gluster服务
Server# modprobe fuse
Server# /etc/init/glusterd start
服务器只有一台,直接创建Volume即可,名为single-volume
Server# gluster volume create single-volume 192.168.113.173:/home/single1
启动volume
Server# gluster volume start single-volume
查看当前所有volume状态
Server# gluster volume info
若要使用Cache,则使用
Server# gluster volume set single-volume performance.cache-size 1GB
Gluster自动生成配置文件,在/etc/glusterd/vols/single-volume/文件夹中
在客户端挂载gluster镜像,客户端直接使用Server端的配置文件,不必创建自己的配置文件了
Client# modprobe fuse
Client# /etc/init/glusterd start
Client# mount.glusterfs 192.168.113.173:/single-volume /mnt/local-volume
2.在两台服务器上建立Distributed Volume
假设服务器A为:192.168.113.173(ServerA)
假设服务器B为:192.168.113.174(ServerB)
假设客户端为:192.168.113.179(Client)
首先配置Server,开启gluster服务
ServerA# modprobe fuse
ServerA# /etc/init/glusterd start
ServerB# modprobe fuse
ServerB# /etc/init/glusterd start
服务器有两台,要先绑定在一起(假设使用ServerA做主服务器)
ServerA# gluster peer probe 192.168.113.174
创建Volume,名为cluster-volume
ServerA# gluster volume create cluster-volume 192.168.113.173:/home/cluster1 192.168.113.174:/home/cluster2
启动volume
ServerA# gluster volume start cluster-volume
查看当前所有volume状态
ServerA# gluster volume info
若要使用Cache,则使用
ServerA# gluster volume set cluster-volume performance.cache-size 1GB
Gluster自动生成配置文件,在/etc/glusterd/vols/cluster-volume/文件夹中
在客户端挂载gluster镜像,客户端直接使用Server端的配置文件,不必创建自己的配置文件了
Client# modprobe fuse
Client# /etc/init/glusterd start
Client# mount.glusterfs 192.168.113.173:/cluster-volume /mnt/local-volume
3.在两台服务器上建立Striped Volume
假设服务器A为:192.168.113.173(ServerA)
假设服务器B为:192.168.113.174(ServerB)
假设客户端为:192.168.113.179(Client)
首先配置Server,开启gluster服务
ServerA# modprobe fuse
ServerA# /etc/init/glusterd start
ServerB# modprobe fuse
ServerB# /etc/init/glusterd start
服务器有两台,要先绑定在一起(假设使用ServerA做主服务器)
ServerA# gluster peer probe 192.168.113.174
创建Volume,名为stripe-volume
ServerA# gluster volume create stripe-volume stripe 2 transport tcp 192.168.113.173:/home/stripe1 192.168.113.174:/home/stripe2
启动volume
ServerA# gluster volume start stripe-volume
查看当前所有volume状态
ServerA# gluster volume info
若要使用Cache,则使用
ServerA# gluster volume set stripe-volume performance.cache-size 1GB
Gluster自动生成配置文件,在/etc/glusterd/vols/stripe-volume/文件夹中
在客户端挂载gluster镜像,客户端直接使用Server端的配置文件,不必创建自己的配置文件了
Client# modprobe fuse
Client# /etc/init/glusterd start
Client# mount.glusterfs 192.168.113.173:/stripe-volume /mnt/local-volume